はじめに
こんにちは、機械学習の活用を加速させるために学習インフラの開発やワークフロー自動化に取り組むチームに所属している澁井です。今回は自動運転のためのデータ検索基盤を自作した話を書きます。
なお、ティアフォーでは「自動運転の民主化」をともに実現していくエンジニアを募集しています。今回ご紹介する機械学習だけではなく、様々なバックグラウンドをお持ちの方と開発を進めていく必要があります。下記ページから募集職種のリストをご覧いただき、興味を持った方はぜひお気軽にご連絡ください!
さて、ティアフォーでは自動運転に機械学習を活用しています。主な機械学習の用途は画像や動画データを扱った認識技術への応用です。
機械学習では意味づけ(アノテーション)されたデータが大量に必要となります。アノテーションとはネコの画像には「ネコ」、イヌの画像には「イヌ」と画像に意味を付与することです。
自動運転で扱うデータは主に実証実験で各地を走ったデータになり、機械学習の学習データも実証実験で得たデータになります。しかし実証実験のデータはアノテーションされておらず、自動運転を動かしているROS(Robot Operating System)特有のrosbagというデータ形式になっているため、人間が生データを見て理解することはできません。データを分析して学習データを作るためにはrosbagを画像や動画形式に変換し、人間に読めるようにする必要があります。

実証実験で収集するデータ量はビッグデータと呼ぶに相応しく、一日に数TBを超える非構造化データが集まります。実証実験の価値を機械学習にフィードバックするためには収録したデータの中から有益なデータを探索し、学習データに加えられるようにする必要がありました。

社内のデータ活用の状況を確認するため、社内コミュニケーションツールで下記のような質問をしてみました。
質問:rosbagのデータを活用してる方々にオープンに質問なのですが、必要なデータはどうやって検索していますか? たとえば緯度経度や地名による検索とか、年月日、時間帯とか、どういう条件で検索できると便利でしょうか?
回答:ほしい!

その結果、みんなデータを探せなくて困っているものの、データを整備する工数が取れない、ということがわかりました。課題は見つけた人が解決する精神で、私が自分で検索システムを作ることにしました。
課題
まず、ティアフォー社内のデータ活用には3つの課題がありました。
- データを探せない:実証実験で得たデータは社内に大量に貯まっているが、開発者が目的のデータを簡単に見つけられない。
- 保管先がまばら:データは社内ストレージにアップロードされている一方、「どこ」に「いつ」の「どの」データが保管されているのか、統一して整理されていない。
- クラウドを使わない:データがクラウドに貯まっているのにローカルの開発端末にダウンロードして使おうとする。
他にも細かい課題は多々ありますが、データ活用を加速して機械学習開発を効率化するためにはデータが探しづらい状態です。ほしいデータを得るためには社内ドキュメントに書かれた実験記録(自動運転で走った場所、日時、天気など)を元に、社内ストレージからrosbagファイルを探してダウンロードし、開発者の端末でrosbagを解凍して必要なデータを探さなければいけませんでした。rosbagは1ファイルで1GB以上のサイズの中に、自動運転中の5、6分程度を記録しています。機械学習に必要なバラエティのあるデータを得るためには5、6分程度では足りません。漏れのないデータセットを作るためには、年間通して場所や明るさ、天気、被写体の位置、大きさ、カメラの方向、自動運転の速度などを組み合わせた多様なデータパターンを用意する必要があります。rosbagファイルをいちいちダウンロードして確認するのはあまりにも非効率です。
そこで、rosbagで収集したデータを検索できるシステムをクラウド上に作ることにしました。検索システムのゴールは社内に散らばったデータを同じインターフェイスで検索し、すぐ利用できるようにすることです。
検索システムをどのように作るか
検索システム開発で立てた目標の一つは、最速で作ってすぐ使える状態にすることです。データは貯まれば貯まるほど整理し使えるようにすることが難しくなります。データベースに登録するだけでも長時間かかりますし、バラエティが増えれば属性の整理やテーブル設計が困難になります。日々数TBの非構造化データが貯まる状況で放っておくことは良策ではありません。もちろんこれまでティアフォーでは検索システムがなくても開発できていたので、自動運転に検索システムは必要ないのかもしれません。しかし、ツールを導入することで仕事が楽になるかどうかは導入してみないとわかりません。検索の有用性(または無用性)を証明するため、スピーディに作ってPoCを進めることも目標としました。
スピード優先で開発するため、検索システムのソフトウェアスタックには下記のすぐ簡単に使えるものを選びました。
- インフラ:Kubernetes(Amazon EKS『2020年でKubernetesクラスターを3回再構築した話』参照)
- データベース:Amazon PostgreSQL Aurora
- バックエンドAPI:Python、FastAPI、SQL Alchemy
- 画面:Python、Streamlit
- データパイプラインとデータの意味づけ:Python、COCOデータセット学習済みEfficientDetの物体検知、TensorFlow Serving
全体像は以下のようになります。

ソフトウェアスタックと全体像からわかるとおり、主な開発言語はPythonです。検索のレスポンス速度を上げるならばJavaやGolangを使ったほうが性能が改善されますが、短い期間で作り切ることを優先してPythonを選びました。ディープラーニングでデータに意味づけするためにはPythonがより扱いやすいという理由もあります。
インフラは以前構築したAmazon EKSのKubernetesクラスターを使っています。個人的にKubernetesが最も楽に使えるインフラになっているからです。データベースは私の好みでAurora PostgreSQLを使っています。
バックエンドAPIはFastAPIとSQL Alchemyで作っています。SQL (Relational) Databases - FastAPIで書かれているデータインターフェイス設計をそのまま参考にしています。Python側のデータスキーマはPydanticで定義することで、関数間のデータ受け渡しで型がわからなくなって実装に迷うことを避けました。型が定まっているとコーディングの手戻りが減ります。
バックエンドAPIはPython+FastAPI+SQL Alchemyで手早く済ませたコンポーネントです。機能とデータが増えてパフォーマンス劣化してきたら、他の言語かgRPCで作り変えてORMも排除すると思います。
画面はStreamlitというPythonをベースにWeb画面を作ってデータを可視化するライブラリを使います。通常はHTML + JavaScriptで作る部分ですが、JavaScriptを書きたくないという個人的な理由でStreamlitを選びました。次はFlutterで作りたいと考えています。
以下の公式の動画のように、コンポーネントをPythonコードで書くことで画面表示を定義できてとても便利です。
StreamlitであればPythonのグラフ作成ライブラリのMatplotlibやSeabornと組み合わせてデータのグラフを簡単に画面に表示できるため、良い選択だったと思います。
データパイプラインとデータの意味づけではrosbagから画像を抽出し、データベースとストレージに登録します。抽出するデータは主に一般道を走る自動運転車のカメラで撮影する画像になります。
意味づけのために物体検知を使い、映っている被写体を判定しています。自動運転の機械学習では、認識のためにカメラに映っている歩行者や対向車、バイク、信号機等を検知します。学習済みの物体検知(EfficientDet)で簡易的に被写体を検知し、検索時に被写体の数で絞り込みできるようにしています。データの意味づけには物体検知以外にも、画像の明るさや逆光、緯度経度と住所、日時と場所をベースにした天気、気温による検索を可能にしています。
データパイプラインはKubernetes Jobで定期的にデータを収集、解凍し、意味づけしてデータベースに登録します。
意味づけのおかげで、たとえば以下のように「信号機」が映っている逆光画像を検索できるようにしています。
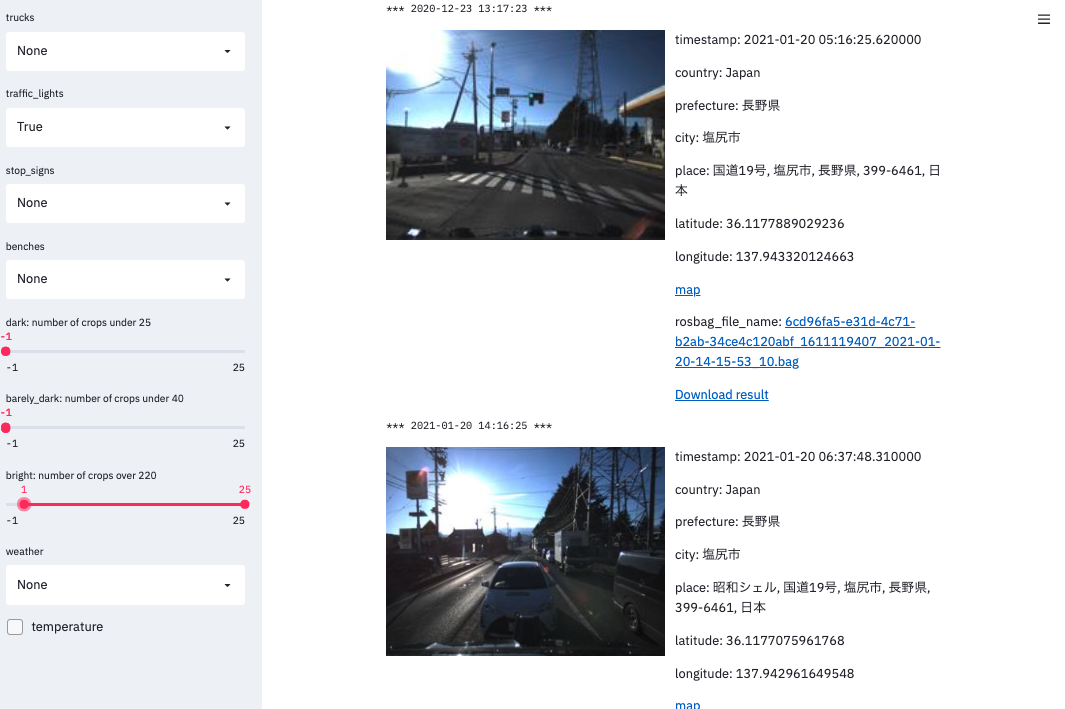
別の例として、天気は「雪」で「自転車」が映っている画像です。

どのくらいの期間で作ったか
上記の構成と機能で検索システムを作りました。
ところどころ再開発するつもりで、さっさと使えるようにすることを優先して開発しています。以下に各コンポーネントの開発所要時間をまとめます。
- Kubernetesは構築済みのクラスターにノードグループを追加し、各コンポーネントを動かすマニフェストを書きました。所要時間は1時間以内です。
- バックエンドAPIとテーブル設計は最低限の機能と正規化にとどめ、2週間程度で開発しています。
- 画面はStreamlitのおかげで3日くらいで作れました。マークダウンやテーブル、チェックボックス等Web画面に必要なコンポーネントをPythonのコード数行で書くことができるため、とても楽に作れました。
- データパイプラインはrosbagを解凍しデータベースとストレージに登録するコードをシングルプロセスで書いています。今後収集するデータ量が増えたら並列処理を検討します。データの意味づけは学習済みの物体検知モデルや簡易的な明るさ評価を活用しています。データの意味づけは開発者の要望を聞きながらオンデマンドで追加していったため所要時間はまちまちですが、1機能1週間程度です。
作ったものを適宜リリースしていく方式で、最初はバックエンドAPIと画面だけを用意し、オリジナルのrosbagデータを取得した日時や場所だけで検索できる状態で社内公開しました。ここまで大体3週間で第1弾をリリースしています。
そこから毎週1機能追加を目標としました。1週間ごとに物体検知、天気や気温による検索、画像の明るさや逆光検索を追加していきました。
他の作業をこなしながら検索システムを作っていたのですが、1ヶ月強で作ったわりには便利なものが作れたと思います。

機能追加時は最初にモック画面と動画を作り、機能のイメージを利用者に共有してから実物を作る流れを取りました。検索の仕様を言葉で要件定義する作業を減らし、見えて使えるものを作ることにこだわっています("Working software over comprehensive documentation"または"Done is better than perfect")。これもスピード優先で作るための工夫です。
もっと検索できるようにしたいデータがあった
ここまで2021年3月中に開発とリリースを進めてきました。社内でデータ検索システムを作っていることを宣伝したおかげで、当初は存在を知らなかったデータや、課題が不明確だったデータ活用のシーンが判明しました。
その一例がアノテーションされたデータの検索です。機械学習で使うデータは外注してアノテーションしているのですが、アノテーションされたデータも画像とJSON形式でストレージに貯まったままで、データベース管理や検索可能化はされていません。アノテーションされたデータが貯まれば貯まるほど、学習条件に合うデータを探すのに人手と時間を要するようになります。そこで、アノテーションされたデータを元データの意味とアノテーションを組み合わせて検索する機能を開発しました。
信号機のアノテーションされた画像(以下は「黄色信号」の含まれる画像)を検索できるようにしています。

この過程でアノテーションされたデータを整理し数量をまとめることになりました。そこで判明したことは、アノテーションは特定のカテゴリに偏っており、本来考慮すべきだが、アノテーションが少ないデータカテゴリが存在することです。日々扱っているデータでも、整理、集計しないと実態を知ることはできないということです。
今回は画像データをターゲットに検索データを作りましたが、その他にもポイントクラウドのデータ等、自動運転には欠かせないデータが残っています。また、社内ストレージから発掘された未知のデータを検索できるようにしたいという要望が出てきています。
個人的には「類似した状況」を条件に検索できるようにしたいと思っています。自動運転では運転中の周囲の状況が運転の判断を左右することがあります。左を並走している自動車が車線変更して先方に入ってきたり、先行している自動車が右折したり、道路幅が狭くなっていたり、周囲に建物があったり、林の中を走っていたり、自転車が並走していたり・・・。多種多様な状況を認識して自動運転するため、こうした「状況」を検索できるようにすることで、状況に応じた運転ロジックの開発を効率化することができると思います。画像や動画を入力にして似ている状況を検索する類似状況検索のようなシステムを作りたいです。
まとめ
データは貯めるだけでもシステム開発とコストが必要となりますが、貯めるだけでなく使える状態にするためにはデータの意味づけと検索が必須になります。データは容量が増えれば増えるほど整理し管理する難しさが増します。加えてデータを使えていない状態では、データを使えない不便さに気づけない事態が頻繁に発生します。データ検索のあり方はデータの使い方や目的次第で千差万別です。今回の開発では素早く作って直しながら、本当に必要なものを目指していく方針がうまくハマりました。
最後に1つだけご紹介させてください。
4月21日にティアフォー初の【Tier IV SUMMIT 2021】をオンラインで開催します!
参加は無料で自動運転の最前線を語ります!ぜひご登録ください!