ティアフォーのSensing/Perceptionチームで開発を行っている村松です。Autowareの動物体検出アルゴリズムのうち一部を再検討し、Autowareに組み込むまでについて紹介します。今回はそのサーベイ編として、調査した概要や手法についてお話します。
なお、ティアフォーでは、「自動運転の民主化」をともに実現していく様々なエンジニア・リサーチャーを募集しています。もしご興味があればカジュアル面談も可能ですので以下のページからコンタクトいただければと思います。
自動運転における3次元物体検出について
3次元物体検出とは、3次元空間での物体のクラス(種類)・位置・大きさ・向きなどを推定する技術です。自動運転において、事故なく目的地まで移動するためには、他車両や歩行者などがどこにどの大きさで存在するかという周辺環境の認識が必須となります。より正確に物体検出を行うことで、自車両がどのように動くか判断することができます。

自動運転車両にはLiDAR(Light Detection and Ranging)やカメラ・レーダーなどのセンサーが搭載されています。その中でも、多くの3次元物体検出手法でLiDARが採用されています。LiDARは、レーザー光を照射し、反射して戻ってくるまでの時間を計測することで空間の位置情報が取得できます。この空間の位置情報が3次元物体検出には重要な特徴量となります。
一方で、単眼画像やステレオ画像からの3次元物体検出も数多く研究されています。しかし、一般的なカメラ画像には深度の情報がないため、RGB(Red-Green-Blue color model)のみから深度を推定する必要があり、特に単眼画像からの推定はとても難しいタスクです。また、カメラのキャリブレーションがかなり正確でないと画像から空間へ投影した際にずれが生じるという難しさもあります。そして、一番大きな問題として学習したカメラ画像のキャリブレーションのパラメータも含めて学習してしまうために、カメラの取り付け位置を変更すると学習したモデルは全く使えなくなってしまうことがあります。オープンソースであるAutowareとしては、センサーの取り付け位置が完全に固定されてしまうことは致命的な問題です。
また、自動運転システムに3次元物体検出手法を組み込む際の計算リソースが限られていることも考慮する必要があります。点群を比較的効率的に処理できるVoxelNet*2と呼ばれる手法があります。VoxelNetについて簡単に説明すると、空間をVoxel化し、点群をCNNs(Convolutional Neural Networks)で処理できる特徴量に落とし込むことで効率的な処理を可能にする手法です。しかし、このVoxelNetには3D CNNsが使われているため、とても大きな計算リソースを必要とします。この問題を解決するためにSECOND*3とPointPillars*4と呼ばれる2つの手法があり、点群をVoxel特徴量に落とし込む3次元物体検出手法のほとんどはこのどちらかをベースとしています。
2つの手法の大まかな特徴は以下のようになります。
SECOND
- 3D CNNsを独自のSparse 3D CNNsに置き換えることで高速化
- 検出精度がよい
PointPillars
- 3D CNNsを除去することで高速化
- SECONDと比較し検出精度は落ちるが軽量で高速
今回、実行時間とAutowareへの組み込みのためのC++への移植性を考慮し、上記2つのうちPointPillarsをベースとする手法を候補にしました。
手法紹介
今回、3次元物体検出を調査した論文として、CenterPoint*5とAFDet*6と呼ばれる2つの手法を紹介します。PointPillarsについては、以前の記事で紹介されているためそちらを参照ください。
Anchor-free Detection
今回紹介するCenterPointとAFDetはAnchor-freeと呼ばれる手法です。従来のPointPillarsなどの手法では、Anchorと呼ばれるBounding Boxの基準となるもので検出範囲内にマッチング検索をし、Intersection over Union (IoU)がしきい値を超えた物体を学習するという手法でした。Anchor-basedの手法では、検索方法やしきい値を適切に決定しなければ、効率よく物体を学習することができません。そのため、より多くの物体がIoUのしきい値を超えるようにヒューリスティックにパラメータ探索をしなくてはなりません(下図a)。
一方で、Anchor-freeの手法では、Anchorを使わずに物体の中心をヒートマップとして学習するため、様々な形状の物体をとりこぼすことがありません(下図b)。
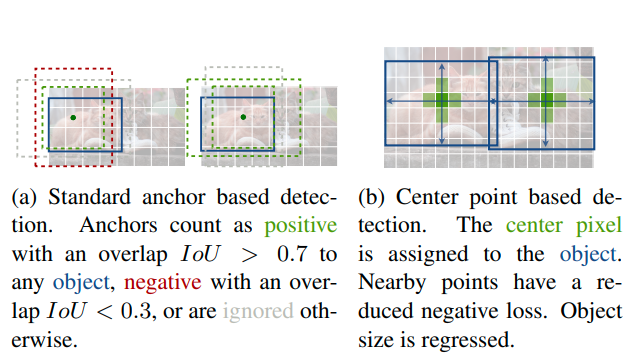
一般的な画像からの物体検出では、上図のように回転のない長方形として物体の位置を示します。しかし、自動運転の3次元物体検出では、物体の向きも考慮する必要があります。また、歩行者や自転車などの小さい物体やトラックやバスなどの長さのある物体なども多く、向きを含めたBounding BoxでIoUがしきい値を超えるようなAnchorを設定するには多くのパラメータやチューニングが必要となります(下図参照)。
Center-based 3D Object Detection and Tracking (CenterPoint)
CenterPointは、The Conference on Computer Vision and Pattern Recognition (CVPR) 2021で採択された論文で、画像から物体検出を行うCenterNet *9を3次元物体検出に応用した手法です。CenterNetの著者も共著者の一人となっており、基本的な考え方については同じものとなっています。
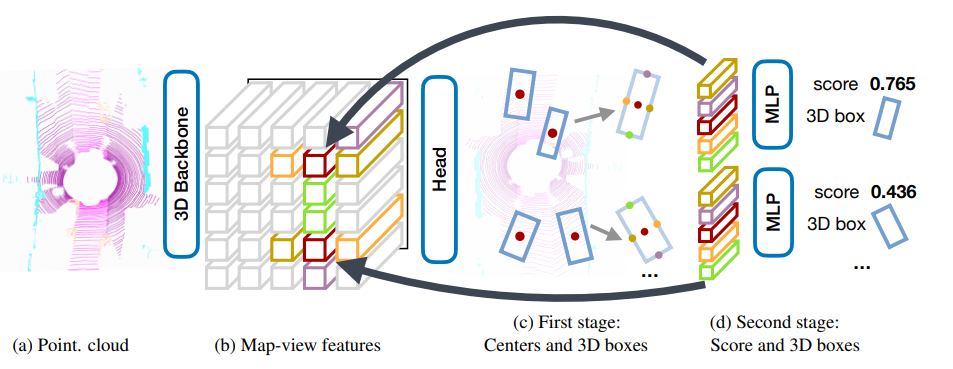
CenterPointの概要について紹介します。CenterPointは3D Backbone、First Stage、Second Stageと主に3つの処理で構成されています。
3D Backboneは点群を入力とし、Bird's-eye-viewの疑似画像特徴量へと変換します。この処理はPointPillarsやSECONDで採用されている手法をそのまま用いているため詳しく知りたい方はそれぞれの論文を参照していただければと思います。
First Stageと呼ばれる処理では、疑似画像特徴量から各物体のパラメータを推定します。まず、ヒートマップのピーク位置から物体の大まかな位置を推定します。次に、各ネットワークの出力からそのピーク位置に対応するオフセットの推定値を用いることで、物体のより詳細な位置を推定します。そして、高さ・サイズ・向きをそれぞれ推定することで、3D Bounding Boxの位置・サイズ・向きが推定できます。
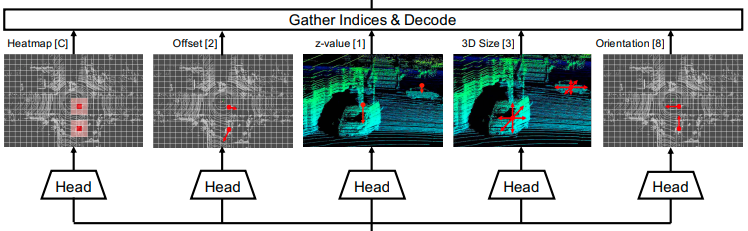
Second Stageでは、First Stageで推定された3次元物体の中心と四辺の中心の位置に対応する特徴量を疑似画像から抽出し、MLP(Multilayer Perceptron)を適用することでScoreと3D Bounding Boxの調節を行います(CenterPointの概要図のd)。
他の3次元物体検出手法と異なる点として、3次元トラッキングを行うために物体の速度推定も行っています。現在のフレームの物体位置と速度から過去フレームの位置を逆算することで、過去の位置に物体が存在した場合に同一物体だと割り当てることができます。
CenterPointは今年のWaymo Open Dataset ChallengeのReal-time 3D Detection分野で2位を獲得しました。そのレポートについてはこちらのリンクにあります。今回の記事の内容は、このコンペティションの前に調査したものなので、コンペティションで使われた手法等の詳しい内容はレポートを参照していただければと思います。
AFDet: Anchor Free One Stage 3D Object Detection
AFDetは昨年のWaymo Open Dataset Challengeの3D Detectionと今年のReal-time 3D Detectionで1位を獲得した手法です。CenterPointとほぼ同じタイミングでarXivに公開されましたが、基本的な考え方はCenterPointのFirst Stageまでの手法と同じです。CenterPointと大きく異なる点は3つあります。
1つ目は、学習時に物体の中心を推定するためのヒートマップの生成方法です。CenterPointではガウス分布を用いていましたが、AFDetでは2点間のユークリッド距離の逆数を用いています。
2つ目は、学習時のオフセットのlossの計算方法です。CenterPointでは物体の中心のグリッドに対応する値のみをlossとして計算しますが、AFDetでは物体の中心に対応する値だけでなく、その周辺のグリッドの値まで含めてlossの計算をします。この方法は、物体のヒートマップのピークが物体の中心とずれていた場合でも、オフセットで物体の中心を正しく推定できるようにすることが目的です。
3つ目は、物体の向きの推定方法です。CenterPointでは向きθをcos(θ)、sin(θ)に分解することで向きベクトルとして学習していますが、AFDetではMulti-binと呼ばれる手法を用いています。この手法は複雑なため簡単に説明すると、θを2つの範囲に区切り、どちらの範囲に入るかの分類とcos(θ)、sin(θ)のregressionを活用することでθを推定する手法です。詳しい内容は論文を参照していただければと思います。
実験
ここまでCenterPointとAFDetについて紹介してきましたが、AFDetは実装が公開されていなかったため、今回はCenterPointのみを検証することにしました。比較対象は、Autowareに実装済みであるPointPillarsです。PointPillarsはAnchor-based、CenterPointはAnchor-freeであることがポイントです。
データセットは規模や画像のBounding Boxのアノテーションも含まれることを考慮してWaymo Open Dataset *12を採用しました。実験にはhttps://github.com/open-mmlab/OpenPCDetのリポジトリを活用しました。
学習条件:
- データセット: trainデータの4分の1
- 検出範囲: -75m ~ 75m四方
- Voxelサイズ: 0.32m x 0.32m x 10m
- Optimizer: Adam
- Scheduler: OneCycle
評価
評価条件:
- データセット: validationデータの4分の1
- 評価方法: nuScenes形式
一般的な画像からの物体検出の評価方法は、主にIoUをしきい値として検出結果にTrue/Falseを割り当てることで計算できるAverage Precision(AP)が使われています。3次元物体検出でも同様にこのAPが使われていますが、このTrue/Falseの割り当て方法では位置や向きのズレをほとんど許容できません。今回は、このズレを許容し物体が検出されていることを優先的に判断するために、nuScenes*13の評価方法である物体の中心間距離をしきい値としてTrue/Falseを割り当ててAPを計算する評価方法を採用しました。nuScenesと同様に中心間距離0.5mをしきい値として用いています。

考察
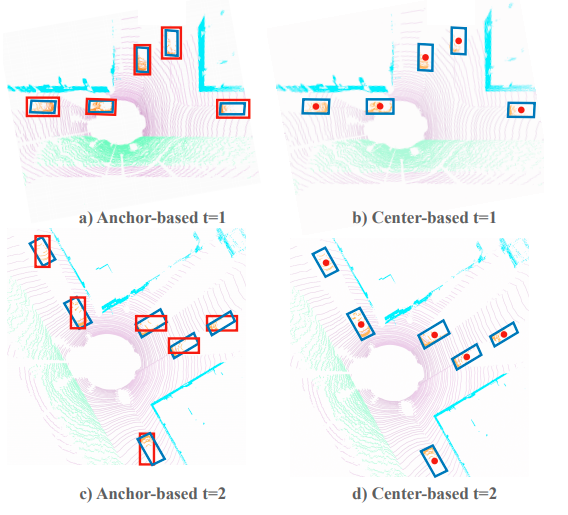
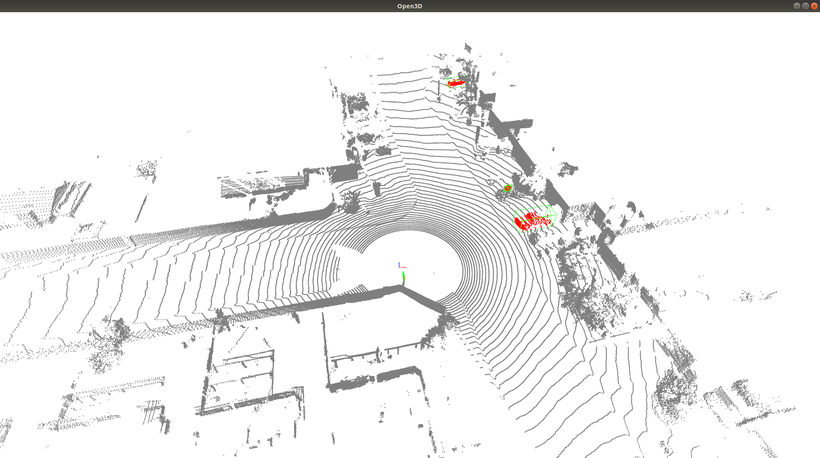
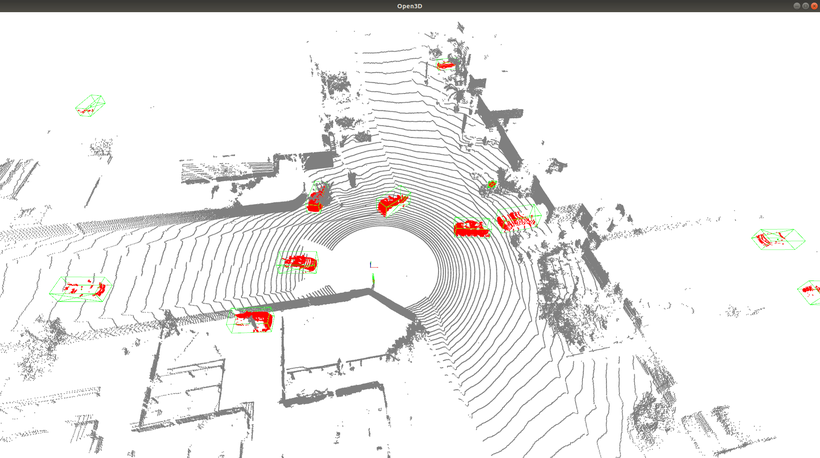
車と自転車はCenterPoint、歩行者はPointPillarsの方が高精度という結果になりました。したがって、この結果から総合的に判断して、Autowareでは既存の動物体検出アルゴリズムと入れ替える形でCenterPointを採用することにしました。
PointPillarsの自転車検出性能がCenterPointより著しく低い理由として、自転車のサンプル数が他のクラスと比べて圧倒的に少ないこと、自転車は小さくて細長い形状のため、Anchorマッチングのしきい値を超えるようなサンプルが少なくなったことが考えられます。学習に使用したデータは、車が約480万サンプル、歩行者が約220万サンプルに対して自転車が約5万サンプルと他のクラスの1~2%にとどまります。
このサンプル数が少ないケースでの問題を解決するために、ground-truth sampling augmentationと呼ばれる手法が多くの論文で採用されています。このground-truth sampling augmentationとは、物体のアノテーションとその物体に対応する点群をデータベースとして保持し、学習フレームにデータベースから物体を追加することで学習するサンプル数を増やすという手法です(下図)。しかし、このフレームに追加されるサンプルは、アノテーションの値をそのまま用いているため学習フレームの幾何的特徴を無視しています。壁や地面にめり込んだ物体や空中に浮いている物体など、現実に存在しない物体も生成し学習してしまいます。これはデータセットの学習フレーム間で似たようなシーンが多い場合には問題ありませんが、立体的な交通環境が多い日本のデータにはそのまま採用できないaugmentationの手法だと考えているため、今回は採用を見送りました。この問題は、地図データを活用することでより現実のデータと整合性のとれるような配置に修正することで解決できると考えています。
まとめ
今回は、3次元物体検出の手法としてCenterPointを採用したところまで紹介しました。次回以降、実際にティアフォーが実証実験を行っている日本の道路環境において物体検出できるよう工夫した方法などについて紹介する予定です。
*1:Ke Chen, et al. "MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views." 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020.
*2:Yin Zhou and Oncel Tuzel. "VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
*3:Yan Yan, Yuxing Mao, and Bo Li. "SECOND: Sparsely Embedded Convolutional Detection." Sensors 18.10 (2018): 3337.
*4:Alex H. Lang, et al. "PointPillars: Fast Encoders for Object Detection from Point Clouds." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
*5:Tianwei Yin, Xingyi Zhou, and Philipp Krähenbühl. "Center-based 3D Object Detection and Tracking." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
*6:Runzhou Ge, et al. "AFDet: Anchor Free One Stage 3D Object Detection." arXiv preprint arXiv:2006.12671, 2020.
*7:Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. "Objects as Points." arXiv preprint arXiv:1904.07850, 2019.
*8:前掲、5に同じ
*9:前掲、7に同じ
*10:前掲、5に同じ
*11:前掲、6に同じ