はじめまして、ティアフォー技術本部 Planning / Controlチームで開発を行っている堀部と申します。
今回は状態推定の王道技術「カルマンフィルター」が実際に自動運転で用いられるまでの道のりやノウハウなどを書いていこうと思います。
みなさんはカルマンフィルターという言葉を聞いたことがありますでしょうか。
カルマンフィルターとは「状態推定」と呼ばれる技術の一種であり、自動運転においては現在の走行状態、例えば車速や自分の位置を知るために用いられます。
非常に有名な手法で、簡単に使えて性能も高く、状態推定と言えばまずカルマンフィルターと言われるほど不動の地位を確立しており、幅広いアプリケーションで利用されています。
使い勝手に定評のあるカルマンフィルターですが、実際に自動運転のシステムとして実用レベルで動かすためには多くの地道な作業が必要になります。
この記事では、カルマンフィルターが実際に自動運転で使われるまでに何が行われているのか、自動運転を支える基礎技術の裏側をご紹介したいと思います。
目次は以下のようになっています。
カルマンフィルターって?
カルマンフィルター(KF:Kalman Filter)の説明は詳しい文献がたくさんありますので、ここは概念的な説明に限定して説明します。
KFの主な目的は、複数の情報を適切に統合し、より精度の高い推定値を計算すること です。ここで言う「複数の情報」とは、「複数の観測値」とそれらの「信頼度」、「対象の運動モデル」、現在の「推定値の信頼度」などです。1960年にアルゴリズムが提唱されてから、長いこと工学分野の第一線で用いられてきました。*1

実際に、自動運転における自己位置推定での使われ方を例に見ていきましょう。
自動運転における観測値とは、車輪エンコーダーから取得できる車速や、IMUの加速度・角速度情報、GPSから得られる位置情報などになります。
これらの情報は単体でも利用可能ですが、例えばGPSの位置情報は絶えずノイズが乗っています。一方で、人間の知識として「車両は真横に移動しない」と言った車両の運動に関する情報を持っています。これらの情報を「車速センサ」や「車両運動モデル」を用いて統合することによって、より精度の高い車両位置を推定することができるのです。
この複数情報の統合に数学的な最適性を取り入れたものがKFとなります。
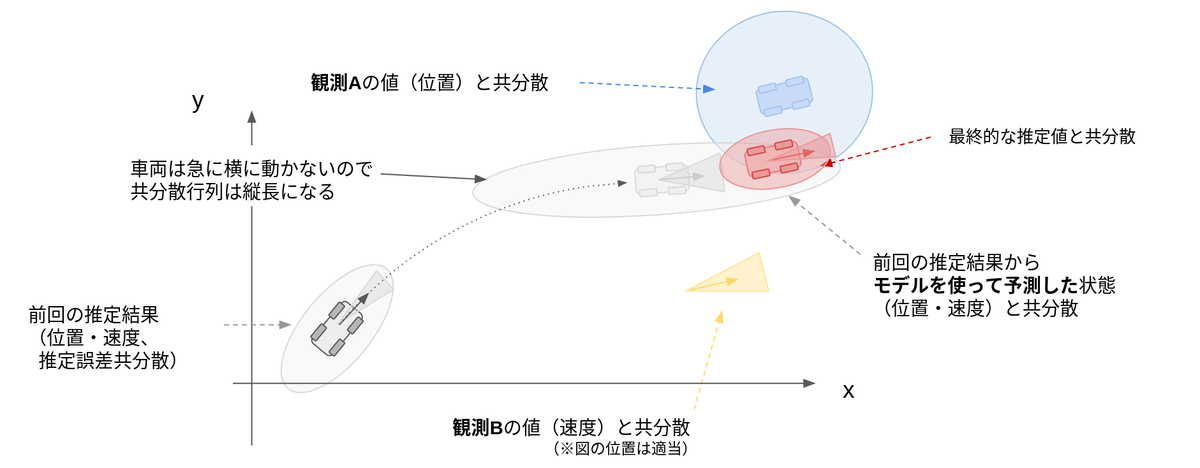
Autowareでどのようにカルマンフィルターが使われているのか
我々の開発する自動運転OS「Autoware」においても、自己位置推定や移動物体のトラッキングなどにKFが使われています。今回は自己位置推定を例に深堀りしていきます。
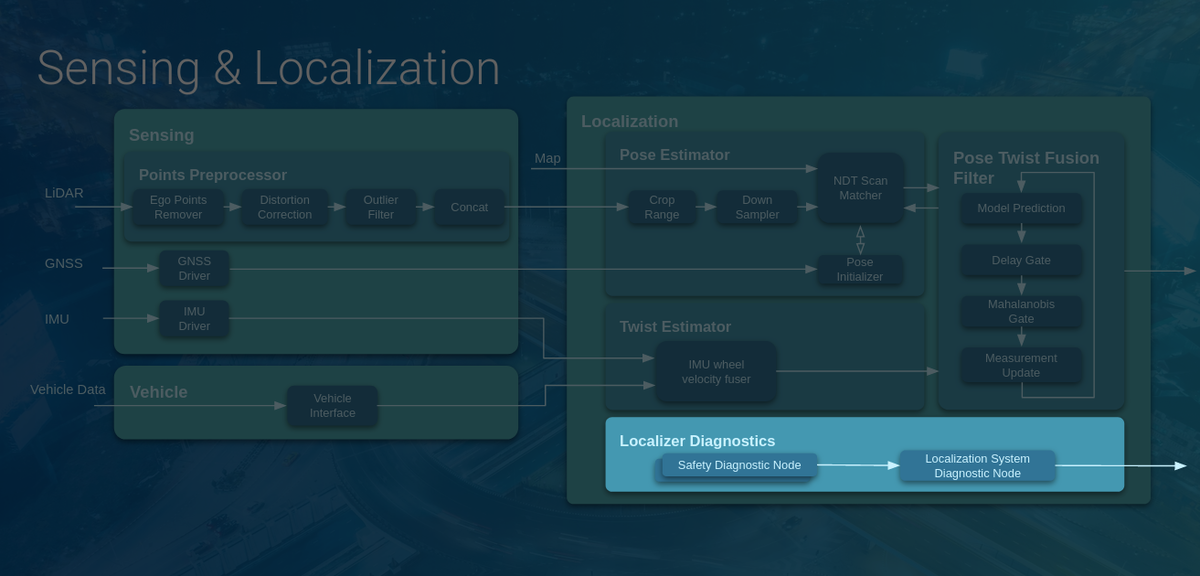
自己位置推定(Localization)とはその名の通り、自分の位置を推定する技術です。下図に、AutowareにおけるSensing/Localizationモジュールの構成図を示しました。右側のLocalizationブロックのPose Twist Fusion FilterにKFが実装されており、Pose EstimatorとTwist Estimatorで計算された自車両のPose(位置・姿勢情報)とTwist(速度・加速度情報)を統合して最終的な推定値を計算することが目的となります。
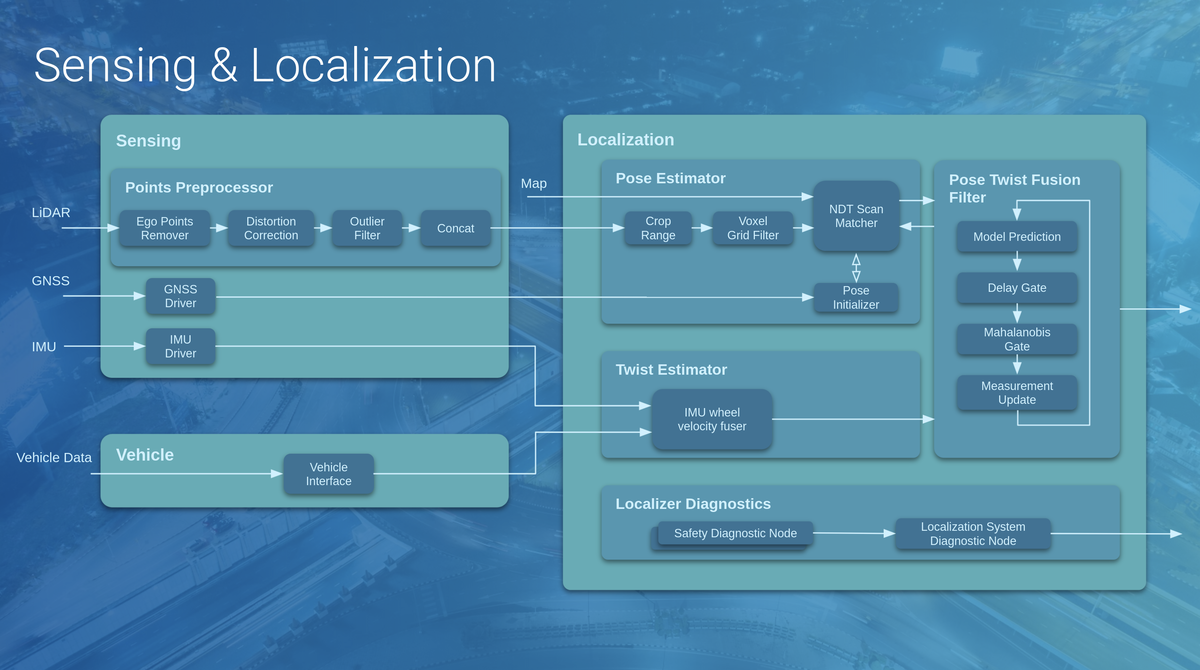
なお、AutowareではPose EstimatorとしてNDT scan matchingと呼ばれる手法を用いており、事前に用意した点群地図(下図:白色)と、自動運転車に搭載されたLiDARセンサーの観測点群データ(下図:赤や黄緑色)を比較して、パズルのように点群が最もうまく当てはまる場所を探し出して自己位置を計算しています。

このNDT scan matching単体でもかなり正確な自己位置を計算することができますが、LiDARのセンサーノイズや外環境の変化により絶えず数センチ程度のノイズが乗っています。ここにKFを導入することにより、推定精度をさらに向上させることが可能となります。
NDT scan matchingについての詳しい情報が知りたい方は過去の記事で述べていますので、こちらをご覧ください。前後編、二部構成の大作となっております。
自動運転の自己位置推定でカルマンフィルターが使われるまで
さて、ここからはいよいよ本題の実装編に入っていきます。
いざ実際にカルマンフィルターを実装すると、特定環境で上手くノイズを除去できなかったり、推定値が一方向にズレる、といった問題が出てきます。
これらの問題の原因は、カルマンフィルターが想定している前提条件と実環境との差異を基準に議論することができます。
例えばカルマンフィルターは「センサーデータのノイズは白色ガウス分布である」といった仮定に基づいて最適化を行います。白色ガウス分布とは非常に理想的な形状をしているノイズなのですが、実環境でノイズがこのような理想形状をしていることは稀であり、自動運転においても例外ではありません。
センサーの遅延を例に見てみましょう。どんなセンサーにも遅延は存在しますが、通常のカルマンフィルターではセンサーデータに遅延が含まれることは想定していません。従って、特別な対処をせずにカルマンフィルターを適用すると、この遅延は白色ガウスノイズであるという仮定の下で処理されます。この仮定は実際のノイズ特性とは大きくかけ離れたものであり、推定精度の劣化に繋がります。
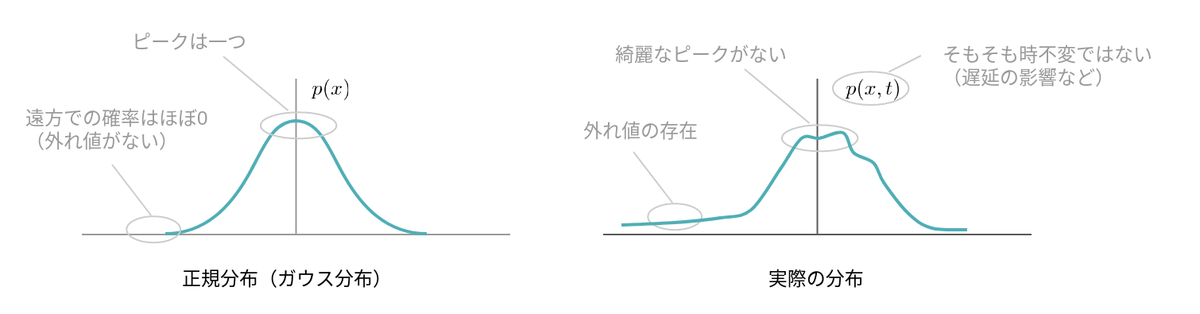
カルマンフィルターの想定する仮定を乱す要因は他にもあり、例えば
- 運動モデルの非線形性
- 外れ値の存在
- ノイズの多峰性
などです。これらの原因を見定め、1つずつ適切な対処をしていくと、仮定と現実の乖離が徐々に小さくなり、最終的な推定精度が向上していきます。
以下では代表的な問題と、その対応について解説します。
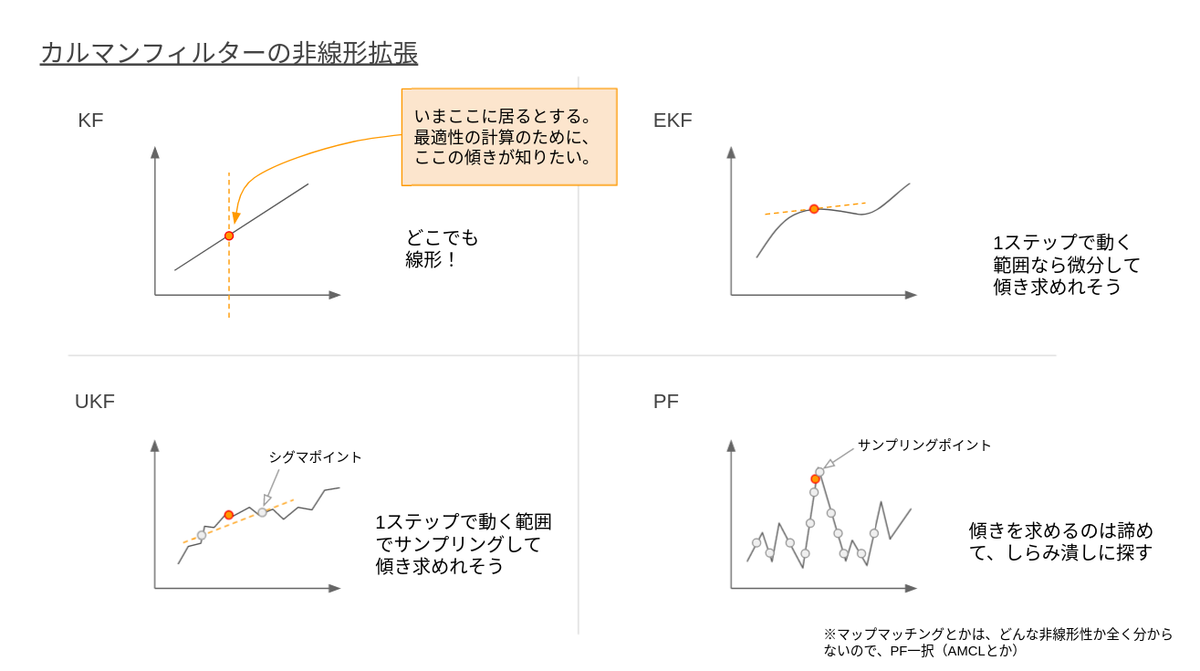
車両運動の非線形性(非線形拡張)
まずは非線形拡張についてです。ここはご存知の方も多いかと思います。
本来KFは線形モデルに対して理論が構築されたものでした。一方で車両の運動は非線形の数式で表されます。以下の式を見てみましょう。
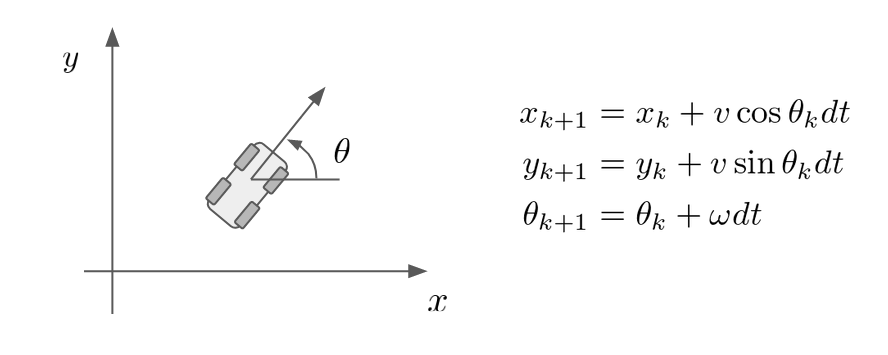
この式は車両が速度v、角速度ωで走行しているときの運動を簡易的に表現したものであり、上の二行の式によって「車両は自分が向いている方向に進む」ことを表しています。ここで問題になるのがsinとcosの存在です。彼らの存在によって式は非線形となってしまい、通常のKFでは対処できません。
この非線形への対処はすでに多くの方法が提案されています。有名なものではExtended Kalman Filter (EKF)、Unscented Kalman Filter (UKF)、Particle Filter (PF) などがあり、対象となる非線形性の強さなどに応じて利用するアルゴリズムを使い分けます。
これらのアルゴリズムは非線形性への対応度と調整・計算コストのトレードオフとなっています。例えば、最も柔軟に非線形に対応できるParticle Filterと呼ばれるアルゴリズムは、一方で非常に計算コストが高く、出力結果にランダム性が生じるといった課題もあり、モデルの非線形特性を適切に理解した上でアルゴリズムを選定する必要があります。
Autowareでは現在はEKFと呼ばれる手法を用いて非線形モデルに対応しています。
センサーに遅延がある(遅延補償)
センサーには必ず遅延が存在します。例えばティアフォーで利用している回転式のLiDARは100msかけて360度のスキャンを行うため、平均50msの遅延が存在します。また、KFの前段のNDTによる計算処理も数10msの時間を要します。
数10msと言われると誤差のようにも聞こえますが、高速で移動する自動運転においてこの遅延は致命的であり、例えば時速60kmで走行中に自己位置推定に100msの遅延が生じたとすると、それだけで約1.7mの誤差を生み出します。
AutowareではAugmented State Kalman Filterと呼ばれる手法を用いて遅延補償を行っています。これはKFの状態を時間方向に拡張し、「過去の状態」を陽に考慮することによって遅延に対応する手法であり、これによって遅延を含んだ情報を、拡張された次元の一部が遅延無しで観測されたとみなすことができます。

詳しくはこちらの書籍 *2 にまとめられています。
(こちらは1979年の論文集なのですが、遅延よりも先にデジタル処理による離散化の影響と補償法について述べられています。当時は計算機の処理が遅く、KFの処理自体に時間がかかっていたのでしょう。こういった時代背景も踏まえて論文を読むといろいろな発見があって面白いですね。)

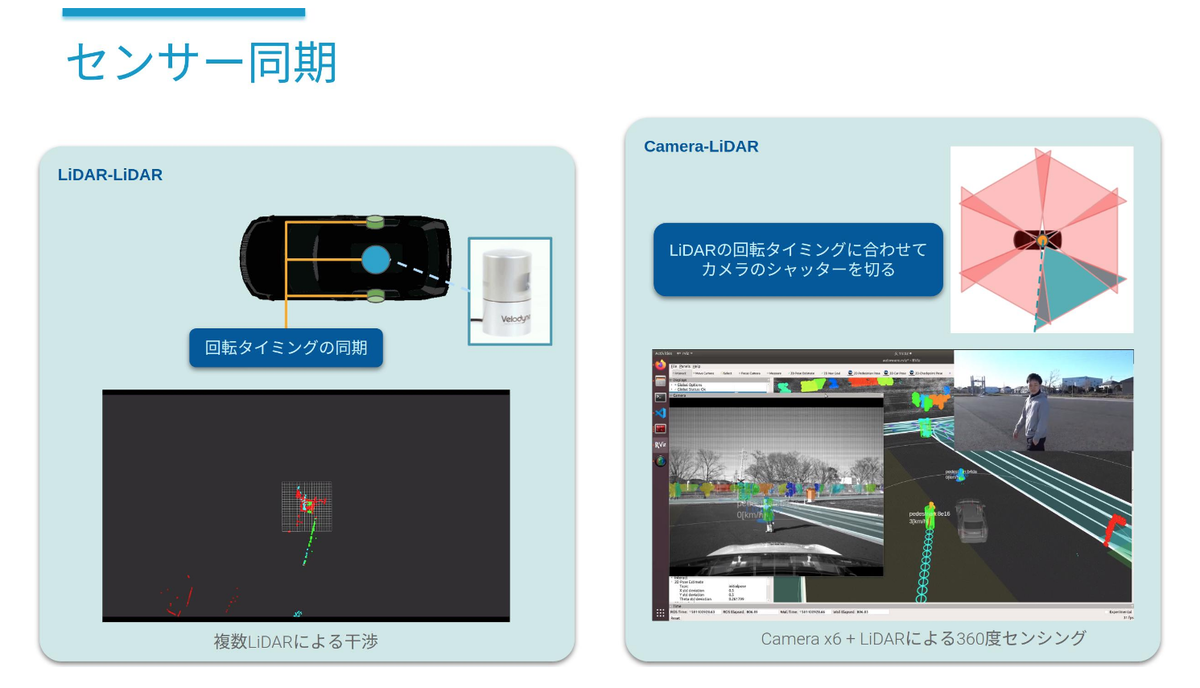
センサー間の時刻同期(センサー同期)
さて、KFを使って遅延に対処する方法が分かりました。しかし、肝心の遅延時間はどのように測定するのでしょうか。
センサーが観測をした真の時間を知る必要があるのですが、ここでもいくつか問題が生じます。それが時刻同期やタイミング同期です。
時刻同期はイメージしやすいと思います。センサーが観測した時刻を知るためには、センサーの時刻ソースと自動運転システムの時刻ソースを揃えたり、観測〜データ受信までの遅延を事前計測しておく必要があります(センサ側でタイムスタンプが得られる場合は前者、出来ない場合は後者)。自動運転には多くの計算機が搭載されており、それぞれの時刻を全て同期させる必要があります。
タイミング同期は、複数センサーの観測タイミングを制御する仕組みです。Autowareでは複数のLiDARデータから得られた情報を結合し、一つの大きなデータとして処理します。このときそれぞれのLiDARが異なるタイミングでスキャンを実行していては、空間的なズレが生じてしまい適切な結合が出来ません。そこで、全てのLiDARの動作タイミングを同期し、仮想的に一つの大きなLiDARが回転しているように振る舞わせることによってこの問題に対処しています。
また、このセンサー同期には他にもいくつかの目的があり、LiDAR同士の干渉問題の解決や、動物体検出におけるLiDAR-カメラフュージョンの性能向上にも一役買っています(下図参照)。
これはこれで話が広がる部分ですが、また次の機会に。
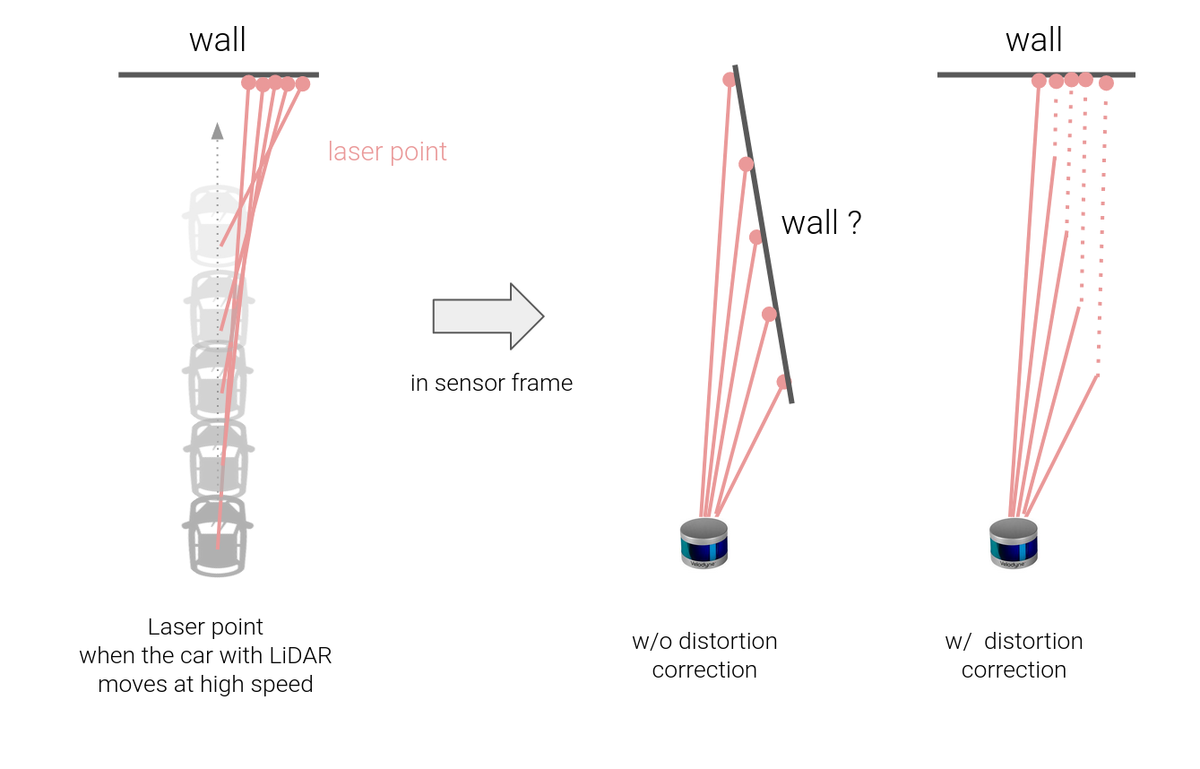
取得した点群が歪んでいる(歪み補正)
時間方向の点群の歪みも問題になります。
LiDARの「一定時間かけてデータを取得する」という特性上、データ取得の開始・終了時点で車両位置が違う、という問題が出てきます。このため、LiDARの生データをそのまま「特定の時刻の情報」として扱うことはできません。
これはカーブ走行時などに特に顕著に現れ、低速走行においても大きな測定誤差を生じます。
この問題を解決するため、AutowareではLiDARの取得点群一つ一つに時刻を埋め込み、その時の車速・角速度情報を用いて点群に時刻補正を掛けるという対応を行っています。
これによって自車の移動に依存しない安定した点群を取得することが可能となり、自己位置推定の精度が大幅に向上します。
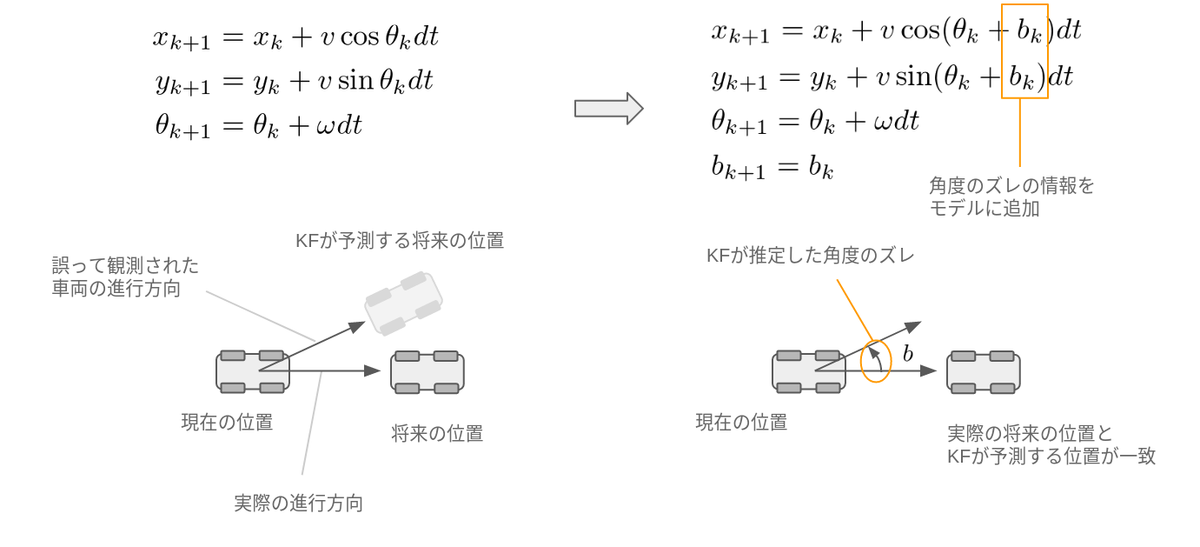
モデルに誤差がある(バイアス誤差モデル)
次は車両モデルの誤差についての話です。例として、LiDARセンサーの取り付け角度がズレている場合を考えてみます。
NDT scan matchingはセンサーによって得られた点群によって自己位置を推定しますが、あくまでも推定できるのはセンサーの位置姿勢であり、センサーと車両の位置関係は事前に与える必要があります。
この位置関係が間違っているとどうなるでしょうか。
例えば下図のように、実際の車両は右に向かって走行していますが、センサーが誤って斜め上の方向に向かって取り付けられており、車両の向きを間違って推定してしまったとします。すると、KFが推定する位置と実際の位置に乖離が生じます。これはKFから見るとノイズの一種なのですが、常に特定方向に偏ったノイズが与えられてしまい、これは事前に説明した白色ガウスノイズの仮定から逸れてしまいます。結果、常に推定結果が横に逸れた状態で計算されます。
これは適応オブザーバー(外乱オブザーバー)と呼ばれる方法を用いて解決されます。
適応オブザーバーとは、KFのモデルに「センサーの取り付け角度がズレる可能性があるよ」という情報を付加することによって、走行中にこのズレを自動で推定する手法です。
実際には、このセンサーの取り付け誤差は走行前のセンサーキャリブレーションによって取り除かれます。
一方で、どうしても事前に取り除けない誤差、例えば温度変化によるヨーレートセンサーのバイアス項や、空気圧変化によるタイヤ径の変化、路面環境の変化などは、このように動的な補償によって対処する必要があります。
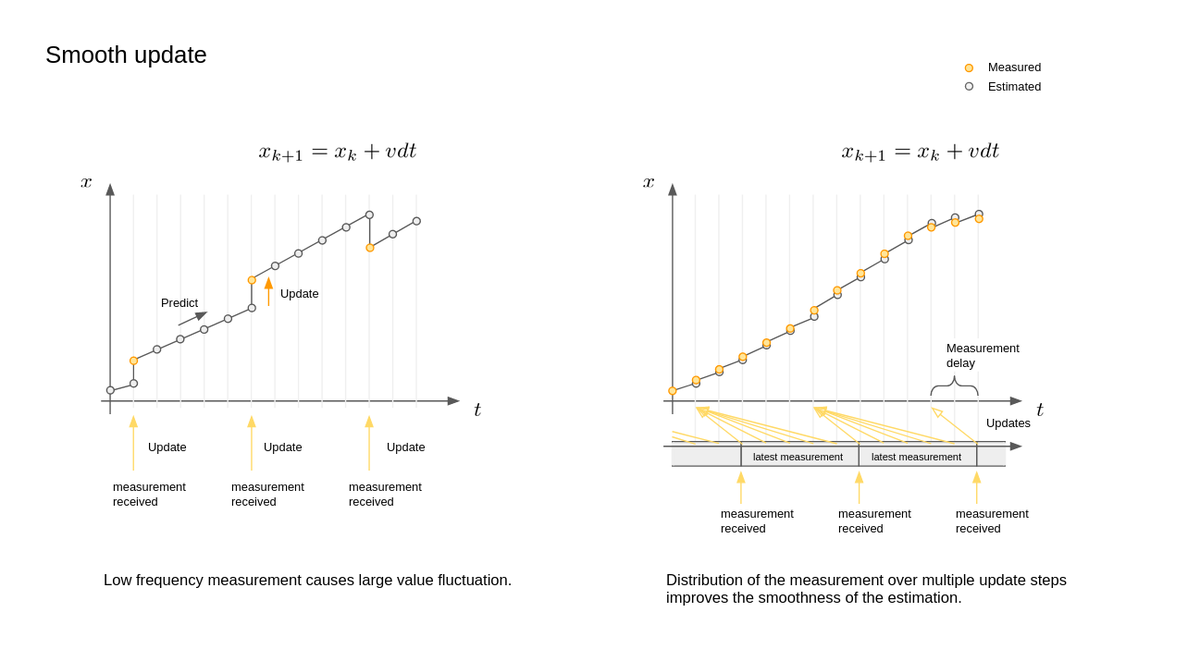
周期の異なるセンサーの統合(滑らかな補間)
複数のセンサー情報を統合するKFの技術は、センサーフュージョンと呼ばれることもあります。ここで問題になるのがセンサーごとの周期の違いです。
例えば、IMUのような内界センサーは数100~数1000Hzで情報を出力することができる一方、NDT scan matchingのような外界センサーに依存した手法は(現在は)10~20Hzでしか情報を出力できません。これらのセンサー周期の違いを考慮せずに統合してしまうと、低周期のセンサー情報がKFに統合されたときに大きく自己位置が変化する、という現象が発生します(下図:左側)。
この「大きな自己位置の変化」自体はKFとしては正常な動作であり、その瞬間にもっとも信頼度の高い位置を出力しているだけに過ぎません。それに対して、この自己位置を車両制御で用いる際には、自己位置のズレがステアの振動に直結するため問題が生じます。
AutowareのKFでは、自己位置の変動に大きな影響を及ぼす情報が得られた場合は、その入力を時間方向に分散させて更新を掛けることによって、滑らかな自己位置の遷移を行っています(下図:右側)。
これは、遅延補償機能との合わせ技であり、遅れて更新を掛けても適切に処理可能であるという前提に基づいています。
急に自己位置が変な場所へ飛んでしまう(外れ値除去)
続いて、センサーの外れ値対応についてです。
例えばGPSのキッドナップ問題と呼ばれる有名な課題があり、GPS信号のマルチパスなどによって、急にGPSの位置が大きくズレることがあります。NDTも同じく、アルゴリズムが収束しなかった場合などは推定値が大きく真値から外れます。
KFはガウスノイズを仮定しているという性質上、外れ値に大きく引きずられるという特徴があり、これらの外れ値は別途対応する必要があります。
Autowareではこの外れ値判定に2つのゲートを設けて対応しています。
まず、NDT側でイテレーション回数などの内部情報を元に外れ値・アルゴリズムの失敗を検出し、計算結果がおかしい場合は結果を出力しないという方針を取っています。これは基本的にワンショットの情報(これまでの時系列の統計情報を含まない情報)で判断されます。
その後段で、KFによって時系列情報を用いた外れ値判定(マハラノビスゲート)を適用します。KFでは推定結果の信頼度(誤差共分散)を内部情報として蓄えており、この情報を元に、KFへの入力がどれだけ確からしいのかを計算することができます。
例えば、これまでの入力の信頼度が低く十分な推定ができていない場合に、実は自己位置の場所が大きく異なっていましたと言われたら、その値は考慮すべきです。一方で、すでに十分な推定精度が得られている場合は、たとえ外部情報が自信満々に値を出してきたとしても、それがあり得ない確率であればその入力を棄却する必要があります。この外れ値の計算にはマハラノビス距離と呼ばれる、入力ベクトルの距離を共分散行列で正規化した値が用いられており、確率論ベースで情報の統合・棄却を判定します。

今の推定精度はどれくらいなのか(共分散の検討)
上節で、共分散行列を元に推定値の信頼度を計算するという話をしました。この「信頼度が計算できる」というKFの機能は非常に有用であり、自動運転の安全性に大きく影響します。
例えば、自己位置の推定精度が悪い場合はレーンからはみ出てしまう可能性があるため、速度を落として走行したり、停止することが求められます。
しかし、この信頼度を正確に計算するためには、KFで統合される信号のノイズ情報が正しく設定されている必要があり、「運動モデルがどの程度正しいのか」「どのくらいのズレがあるのか」「観測値の誤差はどのようなノイズ特性を持つのか」などを一つ一つ検証する必要があります。
このノイズ情報の設定はなかなかに骨の折れる作業で、"How To NOT Make the Extended Kalman Filter Fail" *3という論文で取り扱われるほど多くのエンジニアを悩ませてきた問題です。
例えばIMUのヨーレートセンサーのノイズです。まずは真値と比較を行い、ノイズ情報(二次モーメント)を計算します。このときのノイズ特性が、どれだけKFの仮定(白色ガウス)とズレているのか、が大きなポイントとなります。ヨーレートセンサーは一般的にバイアスノイズの影響が大きいため、まずはこのノイズを除去する必要があります。
その他のセンサーや運動モデルにおいても、どうやったら白色ガウス分布からのズレを除去できるのか、除去できない場合はワーストケースを考慮すると共分散はどう設定すべきなのか、などを検討する必要があります。

緊急時の対応
ここまでKFの拡張や精度、外れ値対応などについて述べてきました。しかし、自動運転において「外れ値が来たので無視します」という処理だけでは安全性を担保することができません。
ここでAutowareのLocalizationモジュールを再見すると、Localizer Diagnosticsというモジュールが存在していることが分かります。
このモジュールはAutowareの自己位置推定の機能群を常に監視しており、外れ値が計算された、位置推定の精度が落ちた、などの情報を統合して現在の自己位置推定の状態を判断します。
この診断情報は別のSystemモジュールへ送られ、状態に応じて適切な指示が車両に送られます。例えば、LiDARに依存した自己位置推定アルゴリズムが何らかの異常によって再起不能になった場合でも、内界センサー(車速センサーやIMU)による自己位置推定によってしばらくは走行が可能であり、自己位置の推定誤差が閾値を超過する前に適切な駐車場所を見つけ、路肩に停車するといった動作が可能となります。
最後に
最後まで読んでいただきありがとうございました。
このブログで述べた機能は、いくつか開発途中のものもありますが、大半はOSS(Open Source Software)として利用可能となっています。興味があればぜひ御一見ください。
いろいろと機能の説明をしてきましたが、自動運転技術は発展途上であり、まだまだ開発が必要な領域が残っています。
このブログを読んで、自動運転って面白そう...!と思った方がいましたら、ぜひ一緒に開発をしましょう!下記リンクからお問い合わせをお待ちしています。
*1:Kalman, R. E. (March 1, 1960). "A New Approach to Linear Filtering and Prediction Problems." ASME. J. Basic Eng. March 1960; 82(1): 35–45.
*2:Anderson, B. D. O., & Moore, J. B. (1979). Optimal Filtering. Englewood Cliffs, NJ: Prentice-Hall.
*3:René Schneider and Christos Georgakis. "How To NOT Make the Extended Kalman Filter Fail." Industrial & Engineering Chemistry Research 2013 52 (9), 3354–3362.