この度、TIER IV Tech BlogをMediumに移行しました。最新の記事は以下のサイトをご覧ください。
こんにちは、ティアフォーで認証認可基盤を開発している澤田です。
最近取り入れたProtobufで、素晴らしいREST APIの開発体験をしたのでご紹介します。
なお、ティアフォーではマイクロサービスを支える認証認可基盤を一緒に開発いただけるメンバーを募集しています。ご興味のある方は下記ページからご応募ください。
マイクロサービス間連携のAPI開発において、以下の条件を満たすやり方を探していました。
Go言語で開発する場合はgo-swaggerでも実現できますが、本記事では、Protobufで実現できるgRPC Gatewayとprotoc-gen-validate (PGV)を使った方法をご紹介します。
https://github.com/grpc-ecosystem/grpc-gateway
gRPC GatewayはProtobufの定義からREST APIのプロキシを生成してくれるプラグインです。gRPCサーバの前段に置くことで、REST APIのインターフェイスを提供することができます。
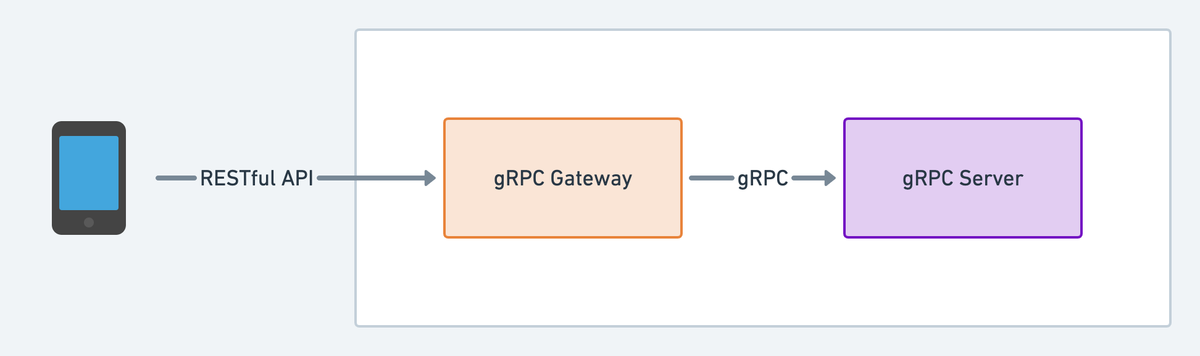
単にREST APIを開発する場合は、gRPCサーバは不要なので、gRPC Gatewayにサービスの実装を登録することができます。

以下の例のように、Protobufから生成されたRegisterXXXHandlerServerを利用すれば、Gatewayにサービスの実装を登録することができます。
mux := runtime.NewServeMux()
err := pb.RegisterEchoServiceHandlerServer(ctx, mux, &EchoHandler{})
if err != nil {
// Error Handling
}
ご参考までにProtobufの定義も載せておきます。message定義の中で必須のフィールドを指定しておくと、swaggerとして吐き出されるときにrequiredとして表現されます。設定を忘れやすいところではありますが、Goの場合は生成したopenapi.yamlからAPI Clientを自動生成し、インテグレーションテストの仕様により必須でないフィールドはポインタになるため、設定を忘れていたことに気づけます。
syntax = "proto3"; package example; option go_package = "./;pb"; import "google/api/annotations.Protobuf"; import "validate/validate.Protobuf"; import "Protobufc-gen-openapiv2/options/annotations.Protobuf"; service EchoService { rpc Echo (EchoRequest) returns (EchoResponse) { option (google.api.http) = { post: "/echo" body: "*" }; } } message EchoRequest { string name = 1; option (grpc.gateway.Protobufc_gen_openapiv2.options.openapiv2_schema) = { json_schema: { required: ["name"] } }; } message EchoResponse { string message = 1; option (grpc.gateway.Protobufc_gen_openapiv2.options.openapiv2_schema) = { json_schema: { required: ["message"] } }; }
ちなみに、生成されるドキュメントはOpenAPI v2なので、v3の形式で欲しい場合は以下のようなツールを使ってさらに変換をかける必要があります。
https://github.com/Mermade/oas-kit/blob/main/packages/swagger2openapi/README.md
また、openapi.yamlからAPI Clientの自動生成はoapi-codegenを利用しています。
https://github.com/deepmap/oapi-codegen
https://github.com/envoyproxy/Protobufc-gen-validate
ProtobufからgRPCのメッセージバリデーションを生成してくれるプラグインです。アノテーションでバリデーションルールを表現できます。
syntax = "proto3"; package examplepb; import "validate/validate.Protobuf"; message Person { uint64 id = 1 [(validate.rules).uint64.gt = 999]; string email = 2 [(validate.rules).string.email = true]; string name = 3 [(validate.rules).string = { pattern: "^[^[0-9]A-Za-z]+( [^[0-9]A-Za-z]+)*$", max_bytes: 256, }]; Location home = 4 [(validate.rules).message.required = true]; message Location { double lat = 1 [(validate.rules).double = { gte: -90, lte: 90 }]; double lng = 2 [(validate.rules).double = { gte: -180, lte: 180 }]; } }
gRPCサーバがある場合は、Interceptorでバリデーションできますが、サービスを登録したgRPC Gatewayで使う場合はInterceptorの出番がなく、またHTTPのMiddlewareレイヤではバリデータが使用できません。そのため、Handler内で request.Validate() メソッドを呼ぶ必要があります。
愚直にHandlerの処理でバリデーションメソッドを呼んでもいいのですが、私のチームでは、専用のレイヤでバリデーションするようにしました。コード量は増えてしまいますが、バリデーションの実装忘れは発生しにくいと思います。
REST APIに限った話ではないのでテーマから少し脱線してしまいますが、開発体験を良くしてくれたBufについても簡単にご紹介させてください。
BufはProtobufの依存管理やprotocで実行していたコマンドをいい感じにまとめてくれるツールです。これを使うことで、 依存管理の悩みから開放され、protocコマンドで長たらしく書いていたものをbuf generateとシンプルにまとめることができます。
https://docs.buf.build/introduction
protoディレクトリをprotoファイルの置き場とした場合、以下のような構成になります。
RepositoryRoot
├── buf.gen.yaml // protoc コマンドの引数ここで定義する
├── buf.work.yaml // workspaceを指定。この場合は proto ディレクトリを指定する
└── proto
├── buf.lock // buf.yaml を作成後、 buf mod update コマンドで自動生成される
├── buf.yaml // .proto ファイルで使用されている依存の定義
└── example
└── echo.proto
BufはBSRというProtobuf(Repository)とプラグインのレジストリを提供しています。
Protobufを提供しているRepositoryは充実していますが、プラグインはBSRに登録されていないことがあります。例えば、protoc-gen-validateのRepositoryはありますが、2022年1月現在プラグインは提供されていないので、プラグインが実行可能なDockerfileを自分で用意、BSRに登録し、使えるようにする必要があります。
今回は、Protobufを使ってREST APIを開発する方法と、ProtobufのツールであるBufについてご紹介しました。バリデーションまでできるスキーマ駆動開発の方法はかなり少ないと感じており、今後しばらくは有力な選択肢の一つになるのではないかと思っています。
こんにちは、ティアフォーでパートタイムエンジニアをしている吉本です。
本記事では、計算量を抑えつつシミュレータ内のNPCロジックをよりリアルにする手法について紹介します。
なお、ティアフォーでは「自動運転の民主化」をともに実現していく、学生パートタイムエンジニアを常時募集しています。 自動運転という活発に研究開発が行われている分野で生き残っていくためには、自社で技術開発を行っていくと同時に常に最新の論文からキャッチアップし続ける必要があり、論文の内容の実装や改良を行っていくなど、幅広い領域でパートタイムエンジニアの募集があります。
まずは「話を聞いてみたい」でも結構ですので、もしご興味があれば以下のページからコンタクトいただければと思います。
シミュレーションチームでは、こちらの記事で紹介があったようにシナリオテストによって自動運転の安全性担保に取り組んでいます。 様々な交通状況のシーンをシナリオに書き起こしてテストを行うわけですが、現在は人間のシナリオライターが行っています。
シナリオでは道路上の車両はもちろんのこと、自転車や歩行者などのNPC(Non Player Character)までもその挙動を細かく指定する必要があります。 この大きな手間を削減するためにシミュレーションチームではBehavior Treeを用いたNPCロジックの強化を行いました。
この改良により、NPCに関してシナリオを細かく指定しなくてもある程度動くようになり、シナリオ書き起こしの作業負荷は大幅に軽減しました。
ただし、これでも短時間に状態間を行ったり来たりするチャタリング問題が起こったり、ある種類のNPCに対して適用した状態機械を他のNPCに流用しようとすると、状態遷移条件が状態の中に記述されているため簡単には流用できない等の問題が残っていて、現行のNPCロジックでは今後多数のシナリオを書いていく際に大きな懸念事項となります。 また、10体以上のNPCが出現するシナリオもあるため、NPCロジックには計算量の少なさが強く求められます。
以上のような問題点を解決するために、私たちはORCA(Optimal Reciprocal Collision Avoidanceの略称)というアルゴリズムを導入することにしました。
今まではシナリオ上で「この速度でこの経路の上を通って動きなさい」といった詳細な”NPCの挙動”を指定していたところを、ORCAでは「この中で動きなさい」というよう動作時に求められる”NPCの挙動の制約条件”を指定するようになっていて、難しい状況に対しても状態のチャタリング現象などが発生することなく動作計画が作れます。
チャタリング現象と言うと難しく聞こえるかもしれませんが、みなさんも歩道などで向こうからやってくる歩行者が右に避けるか左に避けるか分からずに右往左往したことはないでしょうか?
はじめは右に避けることが最適に思えても対向者が同じ方向に避けると最適な避ける方向が左に変わってしまいます。
それを見た対向者が今度は逆の方向に避けようとするともう大変。
同じことが無限ループしてしまい、対面でお互い進路を譲りたいはずなのに妨害して立ち往生してしまいます。
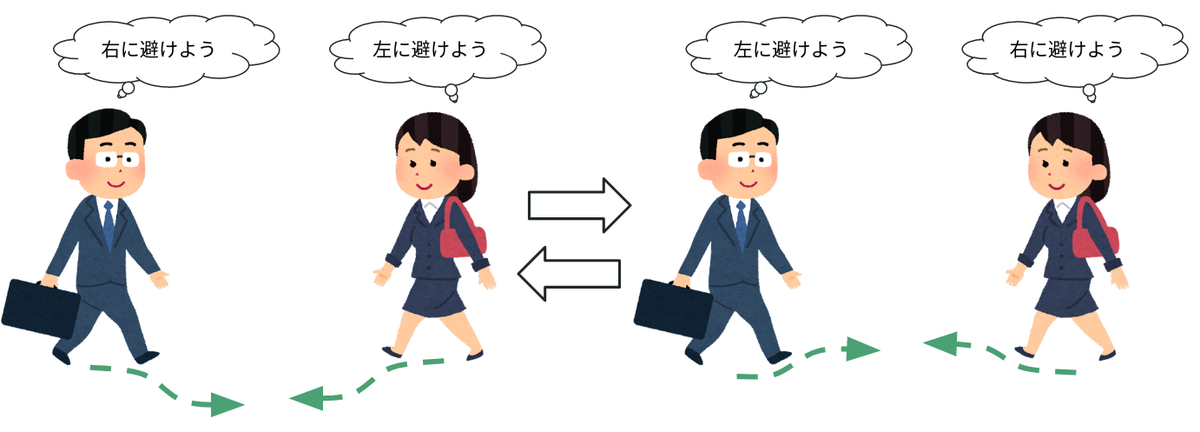
ORCAではそのようなチャタリング現象にもしっかりと対策されているので、導入によりNPCの立ち往生の防止が期待できます。
また、ORCAにおける各NPCの行動計画は独立して計算できるので、並列計算などで計算機のリソースを最大限に活用できます。 また、計算量が少なくなるように設計されていて多数のNPCが出現するようなシナリオでもスムーズに動作します。
ORCAは2010年に提案された衝突回避アルゴリズムです。[1] 提案後も様々な改良がなされ、非ホロノミック拘束をもつエージェントに対応したモデル[2]や、市街地環境で複数のドローンを使って環境を効率よくスキャンするといったマルチロボットでタスクを効率よく実行するための制約条件を入れたモデル[3]等も提案されており、様々な応用先が考えられています。 お互いに意思を持つ多数のエージェント同士が衝突を回避するための行動計画をそれぞれ短い時間で計算できます。 10年経った現在では様々な派生手法が発表されていますが、ベースモデルとしてまだまだ現役で使われています。
ORCAでは、速度空間内でのエージェント同士がぶつからないような線形不等式制約を相対速度と距離から作り出し、制約内で最適な(目標速度に最も近い)速度を計算します。 ORCAのスゴイところは、この計算した線形不等式制約がエージェント同士で通信せずともお互い回避できるような制約になっている点です。 普通なら片方が右に避けるからもう片方は左に避けるといったコミュニケーションをとったり中央集権的なアルゴリズムを用いたくなるものですが、ORCAでは各エージェントごとの行動計画は独立して計算できるため、多数のエージェントが存在する場合でも計算を並列化して高速に計算できます。
この制約条件を近くに存在する他のエージェントに対して計算して(下図)、残った速度空間内で所望の速度に最も近い速度をNPCに適用します。
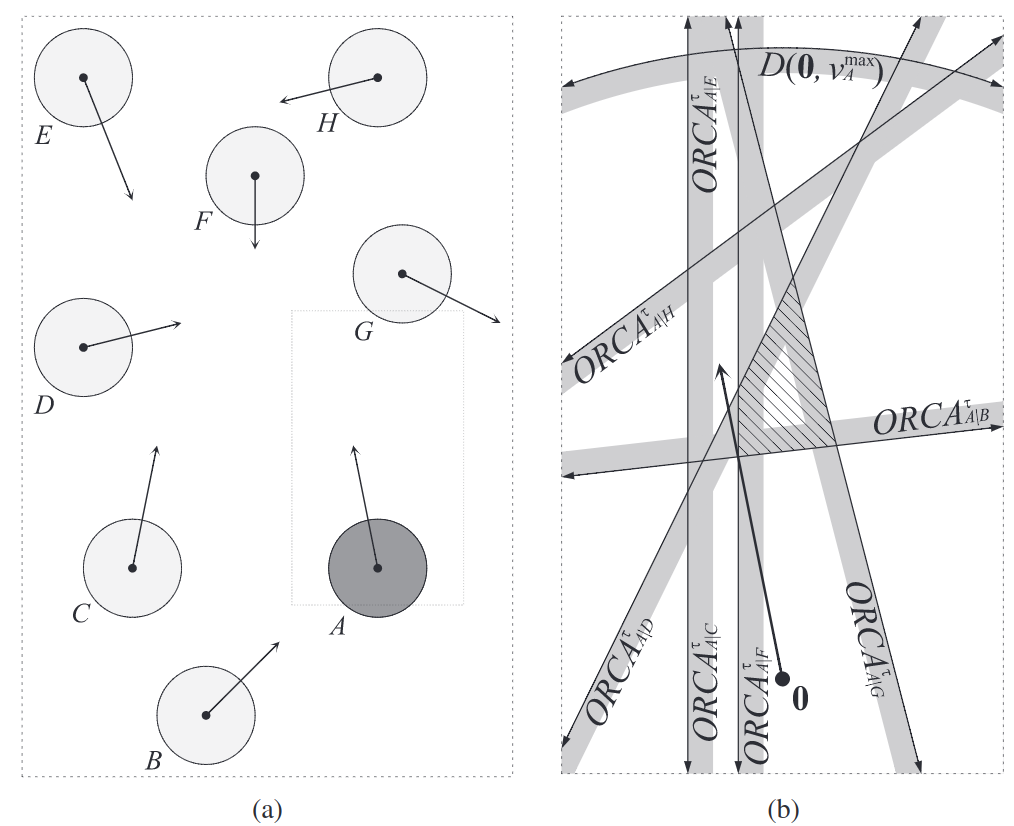
複雑な制約でも線形不等式制約という簡単な制約に落とし込むことで計算が軽くなるように工夫されています。
また、この手法は拡張性の高さも魅力の1つです。 速度空間内の線形不等式制約にさえ落とし込めばその他の制約も追加できるため、例えば自動車なら対向車線に行かないような制約、歩行者なら歩道や横断歩道からはみ出ないような制約を追加することもできるでしょう。
実はOCRAのアルゴリズムはRVO2というOSS(Open Source Software)のライブラリで公開されているので、それをライセンスにしたがって使わせていただいています。 ただし、実際に使うにあたり、NPCの種類や個体ごとにパラメータや避ける障害物を調整できるようにカスタマイズ版を開発しました。 自動車や人などが通行するときには様々な制約のもとで行動しています。 例えば、道路から飛び出さないといった単純なものから信号が赤であれば停止線より前には行かないといった様々な制約があります。 そのため、このORCAモデル単体では賢いNPCを作ることはできず、そこに交通状況のコンテキストを考慮できる機能を導入する必要があります。
そこで現在ティアフォーのシミュレーションチームでは、scenario_simulator_v2のNPCロジックをプラグイン化し、こちらの論文[4]で採用されているContext-GAMMAというORCAに周囲の交通状況のコンテキストを考慮させたモデルにさらにティアフォー独自のアレンジを加えたNPCロジックを実装中です。
具体的には、Context-GAMMA単体では参照経路は事前に与える必要があるので、参照経路をBehavior Treeアルゴリズムを使用して作成、それにおおよそしたがいつつ衝突等は避けるといった感じの挙動をContext-GAMMAを使用して生成します。 まずは歩行者から実装を開始し、次は自動車、自転車、バイクとどんどん対象を広げられればと考えています。
今後もティアフォーのシミュレーションチームではさらなるシミュレータの高度化およびAutowareの評価手法の自動化、効率化を目指します。
[1] Van Den Berg, Jur, et al. "Optimal reciprocal collision avoidance for multi-agent navigation." 2010 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2010.
[2] Alonso-Mora, Javier, et al. "Optimal reciprocal collision avoidance for multiple non-holonomic robots." Distributed autonomous robotic systems. Springer, Berlin, Heidelberg, 2013. 203-216.
[3] Arul, Senthil Hariharan, et al. "LSwarm: Efficient collision avoidance for large swarms with coverage constraints in complex urban scenes." IEEE Robotics and Automation Letters 4.4 2019. 3940-3947.
[4] Cai, Panpan, et al. "Summit: A simulator for urban driving in massive mixed traffic." 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020.
こんにちは、ティアフォーでPlanning/Controlの開発をしている田中です。今回は、交通ルールによって速度を決定するモジュールの一部である死角手前での減速機能を紹介し、この機能が自動運転に与えるインパクトについてお話します。
なお、ティアフォーでは、「自動運転の民主化」をともに実現していく様々なエンジニア・リサーチャーを募集しています。もしご興味があればカジュアル面談も可能ですので以下のページからコンタクトいただければと思います。
通常走行時、Autowareは自車の制限速度にしたがって走行しますが、走行中のレーンに人や車が飛び出してきたときは衝突しないように緊急停止します。閉鎖空間や立ち入り禁止区域など、人が入れないような場所では飛び出しが起こりえないので考慮する必要はありませんが、公道では交差点でないところでも飛び出しは起こりえます。上限速度で走行していた場合は、万が一の飛び出しに対応できない可能性もあります。したがって、緊急停止時にきちんと停止できるかどうかは非常に重要な問題となります。そこで、死角手前から緩やかに減速する機能を開発しました。


自車が走行しているレーン付近に停車中の車両がある場合、その車両の裏が死角となって歩行者が飛び出してくる可能性があるため、停車車両が作る死角地点の十分手前から適切な減速を行います。

衝突前に緊急停止可能な上限速度を \(v_\mathit{ebs}\) とします。\(v_\mathit{ebs}\) は、フルブレーキの減速度 \(a_\mathit{ebs}\) と歩行者が衝突地点にたどり着くまでの時間 \(\frac{d_\mathit{lateral}}{v_\mathit{obstacle}}\) 、システム遅延 \(t_\mathit{safe}\) を用いて以下のように求められます。
\begin{align} v_\mathit{ebs}=a_\mathit{ebs} \cdot \left(\frac{d_\mathit{lateral}}{v_\mathit{obstacle}}-t_\mathit{safe}\right) \end{align}
なお、ここでは死角から出てくる歩行者は \(v_\mathit{obstacle}\) の速度で等速直線運動をするものと仮定しています。
次に、現在地点から死角地点まで一定のブレーキ量で安全に減速するための目標速度の上限を \(v_\mathit{pbs}\) とすると、\(v_\mathit{pbs}\) は現在の自車速度 \(v_0\)、死角までの縦方向距離 \(d_\mathit{longitudinal}\) 、死角手前での減速として許容できるブレーキ量 \(a_\mathit{pbs}\) を用いて、等加速度直線運動の関係式から以下のように求められます。
\begin{align} v_\mathit{pbs}= \sqrt{v_0^2 - a_\mathit{pbs} \cdot d_\mathit{longitudinal}} \end{align}
理論上目標速度に向かって減速しきることが好ましいのですが、誤検出によって死角と判定されたものが急にできたときなどすべての死角に対応できないこと、急減速時の車内の人の安全担保、そして後続車からの衝突回避を考慮して上記の上限速度を用いています。
最後に、走行時に交通の妨げとならないための最低速度定数 \(v_\mathit{min}\) を後続車との車間距離 \(d_\mathit{follow}\)、制限速度 \(v_\mathit{limit}\)、後続車が減速を認識するのにかかる時間 \(s_\mathit{safe}\) を用いて以下のように求めます。
\begin{align} v_\mathit{min}=v_\mathit{limit}-\frac{d_\mathit{follow}}{s_\mathit{safe}} \end{align}
私有地や狭い道路であれば高速で走行する車両は少ないのですが、車の通行量が多い国道や大通りなどではある程度速度を出して走らないと交通の妨げになったり、後続車から追突されてしまうことが考えられます。
これら \(v_\mathit{ebs}\), \(v_\mathit{pbs}\), \(v_\mathit{min}\) を用いて、死角手前での減速計画は以下のようになります。

最後に、死角手前での減速フローを載せておきます。

このように、死角手前であらかじめ減速しておくことで予期せぬ事故を回避できます。今後もより安全な自動運転へ向けた減速計画について検討していきたいと考えています。
この機能の実装には以下の文献を参考にしました。
ティアフォーのSensing/Perceptionチームで開発を行っている村松です。Autowareの動物体検出アルゴリズムのうち一部を再検討し、Autowareに組み込むまでについて紹介します。今回はそのサーベイ編として、調査した概要や手法についてお話します。
なお、ティアフォーでは、「自動運転の民主化」をともに実現していく様々なエンジニア・リサーチャーを募集しています。もしご興味があればカジュアル面談も可能ですので以下のページからコンタクトいただければと思います。
3次元物体検出とは、3次元空間での物体のクラス(種類)・位置・大きさ・向きなどを推定する技術です。自動運転において、事故なく目的地まで移動するためには、他車両や歩行者などがどこにどの大きさで存在するかという周辺環境の認識が必須となります。より正確に物体検出を行うことで、自車両がどのように動くか判断することができます。

自動運転車両にはLiDAR(Light Detection and Ranging)やカメラ・レーダーなどのセンサーが搭載されています。その中でも、多くの3次元物体検出手法でLiDARが採用されています。LiDARは、レーザー光を照射し、反射して戻ってくるまでの時間を計測することで空間の位置情報が取得できます。この空間の位置情報が3次元物体検出には重要な特徴量となります。
一方で、単眼画像やステレオ画像からの3次元物体検出も数多く研究されています。しかし、一般的なカメラ画像には深度の情報がないため、RGB(Red-Green-Blue color model)のみから深度を推定する必要があり、特に単眼画像からの推定はとても難しいタスクです。また、カメラのキャリブレーションがかなり正確でないと画像から空間へ投影した際にずれが生じるという難しさもあります。そして、一番大きな問題として学習したカメラ画像のキャリブレーションのパラメータも含めて学習してしまうために、カメラの取り付け位置を変更すると学習したモデルは全く使えなくなってしまうことがあります。オープンソースであるAutowareとしては、センサーの取り付け位置が完全に固定されてしまうことは致命的な問題です。
また、自動運転システムに3次元物体検出手法を組み込む際の計算リソースが限られていることも考慮する必要があります。点群を比較的効率的に処理できるVoxelNet*2と呼ばれる手法があります。VoxelNetについて簡単に説明すると、空間をVoxel化し、点群をCNNs(Convolutional Neural Networks)で処理できる特徴量に落とし込むことで効率的な処理を可能にする手法です。しかし、このVoxelNetには3D CNNsが使われているため、とても大きな計算リソースを必要とします。この問題を解決するためにSECOND*3とPointPillars*4と呼ばれる2つの手法があり、点群をVoxel特徴量に落とし込む3次元物体検出手法のほとんどはこのどちらかをベースとしています。
2つの手法の大まかな特徴は以下のようになります。
SECOND
PointPillars
今回、実行時間とAutowareへの組み込みのためのC++への移植性を考慮し、上記2つのうちPointPillarsをベースとする手法を候補にしました。
今回、3次元物体検出を調査した論文として、CenterPoint*5とAFDet*6と呼ばれる2つの手法を紹介します。PointPillarsについては、以前の記事で紹介されているためそちらを参照ください。
今回紹介するCenterPointとAFDetはAnchor-freeと呼ばれる手法です。従来のPointPillarsなどの手法では、Anchorと呼ばれるBounding Boxの基準となるもので検出範囲内にマッチング検索をし、Intersection over Union (IoU)がしきい値を超えた物体を学習するという手法でした。Anchor-basedの手法では、検索方法やしきい値を適切に決定しなければ、効率よく物体を学習することができません。そのため、より多くの物体がIoUのしきい値を超えるようにヒューリスティックにパラメータ探索をしなくてはなりません(下図a)。
一方で、Anchor-freeの手法では、Anchorを使わずに物体の中心をヒートマップとして学習するため、様々な形状の物体をとりこぼすことがありません(下図b)。
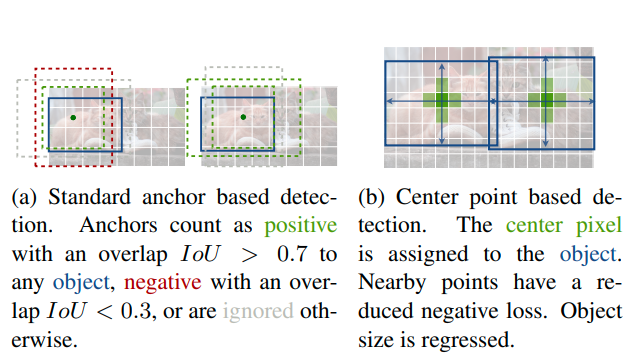
一般的な画像からの物体検出では、上図のように回転のない長方形として物体の位置を示します。しかし、自動運転の3次元物体検出では、物体の向きも考慮する必要があります。また、歩行者や自転車などの小さい物体やトラックやバスなどの長さのある物体なども多く、向きを含めたBounding BoxでIoUがしきい値を超えるようなAnchorを設定するには多くのパラメータやチューニングが必要となります(下図参照)。
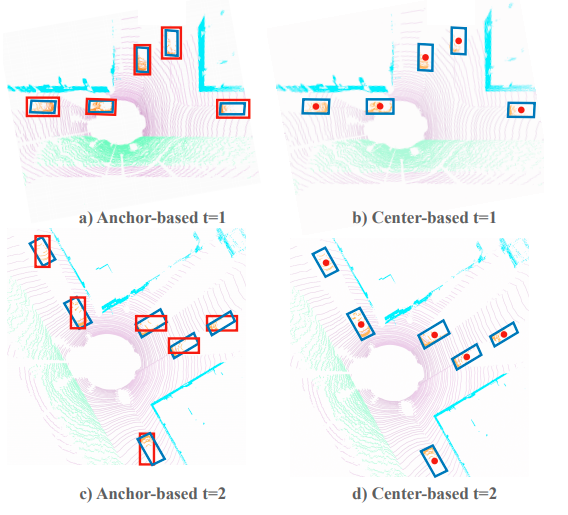
CenterPointは、The Conference on Computer Vision and Pattern Recognition (CVPR) 2021で採択された論文で、画像から物体検出を行うCenterNet *9を3次元物体検出に応用した手法です。CenterNetの著者も共著者の一人となっており、基本的な考え方については同じものとなっています。
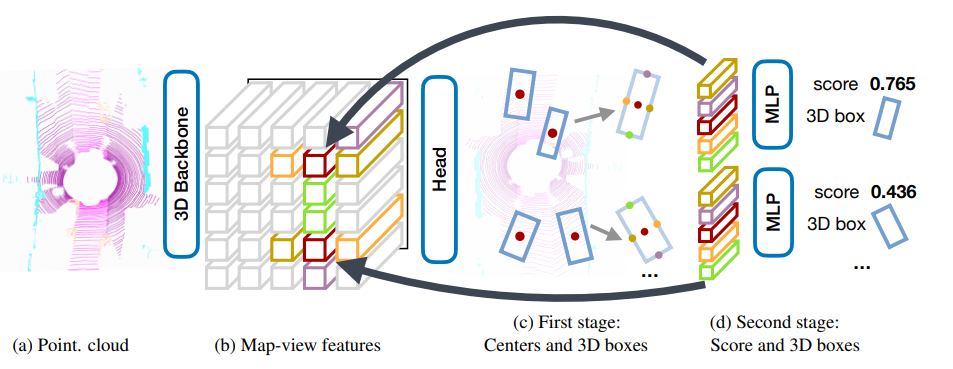
CenterPointの概要について紹介します。CenterPointは3D Backbone、First Stage、Second Stageと主に3つの処理で構成されています。
3D Backboneは点群を入力とし、Bird's-eye-viewの疑似画像特徴量へと変換します。この処理はPointPillarsやSECONDで採用されている手法をそのまま用いているため詳しく知りたい方はそれぞれの論文を参照していただければと思います。
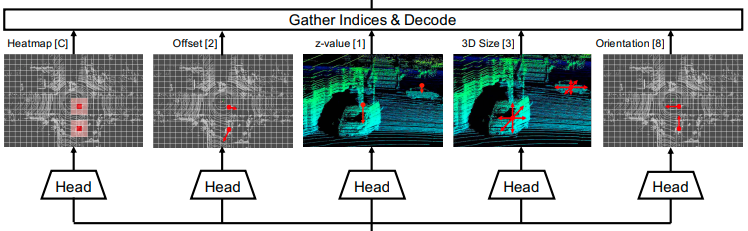
First Stageと呼ばれる処理では、疑似画像特徴量から各物体のパラメータを推定します。まず、ヒートマップのピーク位置から物体の大まかな位置を推定します。次に、各ネットワークの出力からそのピーク位置に対応するオフセットの推定値を用いることで、物体のより詳細な位置を推定します。そして、高さ・サイズ・向きをそれぞれ推定することで、3D Bounding Boxの位置・サイズ・向きが推定できます。
Second Stageでは、First Stageで推定された3次元物体の中心と四辺の中心の位置に対応する特徴量を疑似画像から抽出し、MLP(Multilayer Perceptron)を適用することでScoreと3D Bounding Boxの調節を行います(CenterPointの概要図のd)。
他の3次元物体検出手法と異なる点として、3次元トラッキングを行うために物体の速度推定も行っています。現在のフレームの物体位置と速度から過去フレームの位置を逆算することで、過去の位置に物体が存在した場合に同一物体だと割り当てることができます。
CenterPointは今年のWaymo Open Dataset ChallengeのReal-time 3D Detection分野で2位を獲得しました。そのレポートについてはこちらのリンクにあります。今回の記事の内容は、このコンペティションの前に調査したものなので、コンペティションで使われた手法等の詳しい内容はレポートを参照していただければと思います。
AFDetは昨年のWaymo Open Dataset Challengeの3D Detectionと今年のReal-time 3D Detectionで1位を獲得した手法です。CenterPointとほぼ同じタイミングでarXivに公開されましたが、基本的な考え方はCenterPointのFirst Stageまでの手法と同じです。CenterPointと大きく異なる点は3つあります。
1つ目は、学習時に物体の中心を推定するためのヒートマップの生成方法です。CenterPointではガウス分布を用いていましたが、AFDetでは2点間のユークリッド距離の逆数を用いています。
2つ目は、学習時のオフセットのlossの計算方法です。CenterPointでは物体の中心のグリッドに対応する値のみをlossとして計算しますが、AFDetでは物体の中心に対応する値だけでなく、その周辺のグリッドの値まで含めてlossの計算をします。この方法は、物体のヒートマップのピークが物体の中心とずれていた場合でも、オフセットで物体の中心を正しく推定できるようにすることが目的です。
3つ目は、物体の向きの推定方法です。CenterPointでは向きθをcos(θ)、sin(θ)に分解することで向きベクトルとして学習していますが、AFDetではMulti-binと呼ばれる手法を用いています。この手法は複雑なため簡単に説明すると、θを2つの範囲に区切り、どちらの範囲に入るかの分類とcos(θ)、sin(θ)のregressionを活用することでθを推定する手法です。詳しい内容は論文を参照していただければと思います。
ここまでCenterPointとAFDetについて紹介してきましたが、AFDetは実装が公開されていなかったため、今回はCenterPointのみを検証することにしました。比較対象は、Autowareに実装済みであるPointPillarsです。PointPillarsはAnchor-based、CenterPointはAnchor-freeであることがポイントです。
データセットは規模や画像のBounding Boxのアノテーションも含まれることを考慮してWaymo Open Dataset *12を採用しました。実験にはhttps://github.com/open-mmlab/OpenPCDetのリポジトリを活用しました。
学習条件:
評価条件:
一般的な画像からの物体検出の評価方法は、主にIoUをしきい値として検出結果にTrue/Falseを割り当てることで計算できるAverage Precision(AP)が使われています。3次元物体検出でも同様にこのAPが使われていますが、このTrue/Falseの割り当て方法では位置や向きのズレをほとんど許容できません。今回は、このズレを許容し物体が検出されていることを優先的に判断するために、nuScenes*13の評価方法である物体の中心間距離をしきい値としてTrue/Falseを割り当ててAPを計算する評価方法を採用しました。nuScenesと同様に中心間距離0.5mをしきい値として用いています。

車と自転車はCenterPoint、歩行者はPointPillarsの方が高精度という結果になりました。したがって、この結果から総合的に判断して、Autowareでは既存の動物体検出アルゴリズムと入れ替える形でCenterPointを採用することにしました。
PointPillarsの自転車検出性能がCenterPointより著しく低い理由として、自転車のサンプル数が他のクラスと比べて圧倒的に少ないこと、自転車は小さくて細長い形状のため、Anchorマッチングのしきい値を超えるようなサンプルが少なくなったことが考えられます。学習に使用したデータは、車が約480万サンプル、歩行者が約220万サンプルに対して自転車が約5万サンプルと他のクラスの1~2%にとどまります。
このサンプル数が少ないケースでの問題を解決するために、ground-truth sampling augmentationと呼ばれる手法が多くの論文で採用されています。このground-truth sampling augmentationとは、物体のアノテーションとその物体に対応する点群をデータベースとして保持し、学習フレームにデータベースから物体を追加することで学習するサンプル数を増やすという手法です(下図)。しかし、このフレームに追加されるサンプルは、アノテーションの値をそのまま用いているため学習フレームの幾何的特徴を無視しています。壁や地面にめり込んだ物体や空中に浮いている物体など、現実に存在しない物体も生成し学習してしまいます。これはデータセットの学習フレーム間で似たようなシーンが多い場合には問題ありませんが、立体的な交通環境が多い日本のデータにはそのまま採用できないaugmentationの手法だと考えているため、今回は採用を見送りました。この問題は、地図データを活用することでより現実のデータと整合性のとれるような配置に修正することで解決できると考えています。
今回は、3次元物体検出の手法としてCenterPointを採用したところまで紹介しました。次回以降、実際にティアフォーが実証実験を行っている日本の道路環境において物体検出できるよう工夫した方法などについて紹介する予定です。
*1:Ke Chen, et al. "MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views." 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020.
*2:Yin Zhou and Oncel Tuzel. "VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
*3:Yan Yan, Yuxing Mao, and Bo Li. "SECOND: Sparsely Embedded Convolutional Detection." Sensors 18.10 (2018): 3337.
*4:Alex H. Lang, et al. "PointPillars: Fast Encoders for Object Detection from Point Clouds." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
*5:Tianwei Yin, Xingyi Zhou, and Philipp Krähenbühl. "Center-based 3D Object Detection and Tracking." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
*6:Runzhou Ge, et al. "AFDet: Anchor Free One Stage 3D Object Detection." arXiv preprint arXiv:2006.12671, 2020.
*7:Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. "Objects as Points." arXiv preprint arXiv:1904.07850, 2019.
*8:前掲、5に同じ
*9:前掲、7に同じ
*10:前掲、5に同じ
*11:前掲、6に同じ
はじめまして、ティアフォー技術本部 Planning / Controlチームで開発を行っている堀部と申します。
今回は状態推定の王道技術「カルマンフィルター」が実際に自動運転で用いられるまでの道のりやノウハウなどを書いていこうと思います。
みなさんはカルマンフィルターという言葉を聞いたことがありますでしょうか。
カルマンフィルターとは「状態推定」と呼ばれる技術の一種であり、自動運転においては現在の走行状態、例えば車速や自分の位置を知るために用いられます。
非常に有名な手法で、簡単に使えて性能も高く、状態推定と言えばまずカルマンフィルターと言われるほど不動の地位を確立しており、幅広いアプリケーションで利用されています。
使い勝手に定評のあるカルマンフィルターですが、実際に自動運転のシステムとして実用レベルで動かすためには多くの地道な作業が必要になります。
この記事では、カルマンフィルターが実際に自動運転で使われるまでに何が行われているのか、自動運転を支える基礎技術の裏側をご紹介したいと思います。
目次は以下のようになっています。
カルマンフィルター(KF:Kalman Filter)の説明は詳しい文献がたくさんありますので、ここは概念的な説明に限定して説明します。
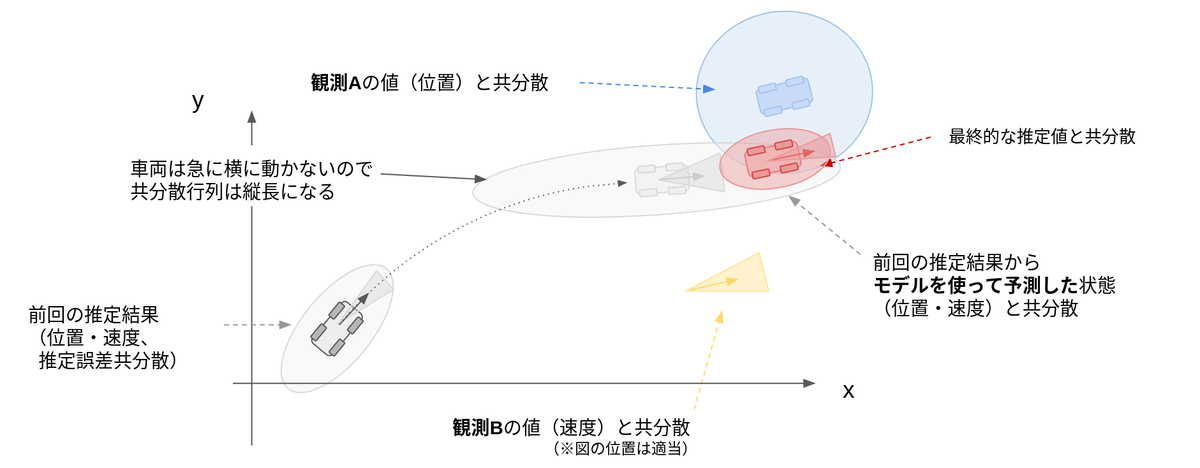
KFの主な目的は、複数の情報を適切に統合し、より精度の高い推定値を計算すること です。ここで言う「複数の情報」とは、「複数の観測値」とそれらの「信頼度」、「対象の運動モデル」、現在の「推定値の信頼度」などです。1960年にアルゴリズムが提唱されてから、長いこと工学分野の第一線で用いられてきました。*1

実際に、自動運転における自己位置推定での使われ方を例に見ていきましょう。
自動運転における観測値とは、車輪エンコーダーから取得できる車速や、IMUの加速度・角速度情報、GPSから得られる位置情報などになります。
これらの情報は単体でも利用可能ですが、例えばGPSの位置情報は絶えずノイズが乗っています。一方で、人間の知識として「車両は真横に移動しない」と言った車両の運動に関する情報を持っています。これらの情報を「車速センサ」や「車両運動モデル」を用いて統合することによって、より精度の高い車両位置を推定することができるのです。
この複数情報の統合に数学的な最適性を取り入れたものがKFとなります。
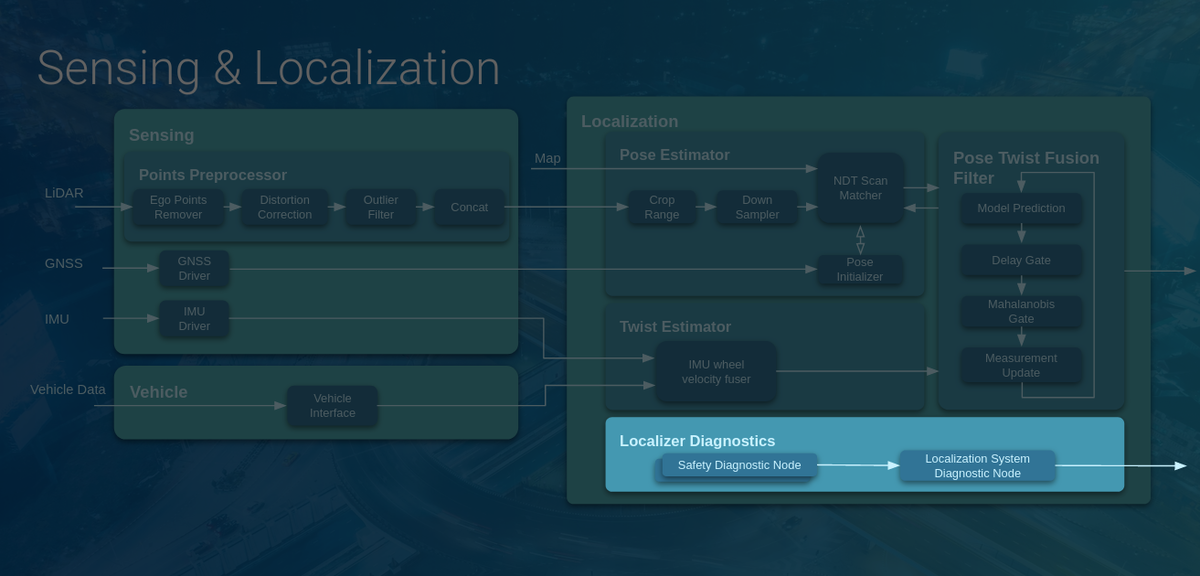
我々の開発する自動運転OS「Autoware」においても、自己位置推定や移動物体のトラッキングなどにKFが使われています。今回は自己位置推定を例に深堀りしていきます。
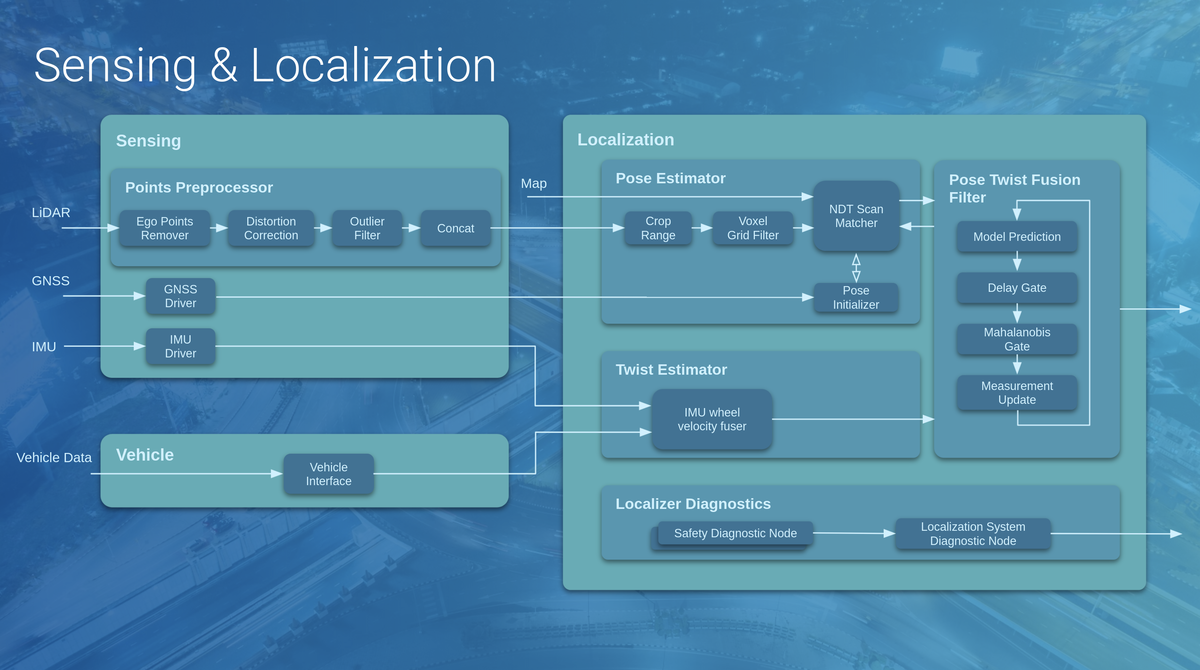
自己位置推定(Localization)とはその名の通り、自分の位置を推定する技術です。下図に、AutowareにおけるSensing/Localizationモジュールの構成図を示しました。右側のLocalizationブロックのPose Twist Fusion FilterにKFが実装されており、Pose EstimatorとTwist Estimatorで計算された自車両のPose(位置・姿勢情報)とTwist(速度・加速度情報)を統合して最終的な推定値を計算することが目的となります。
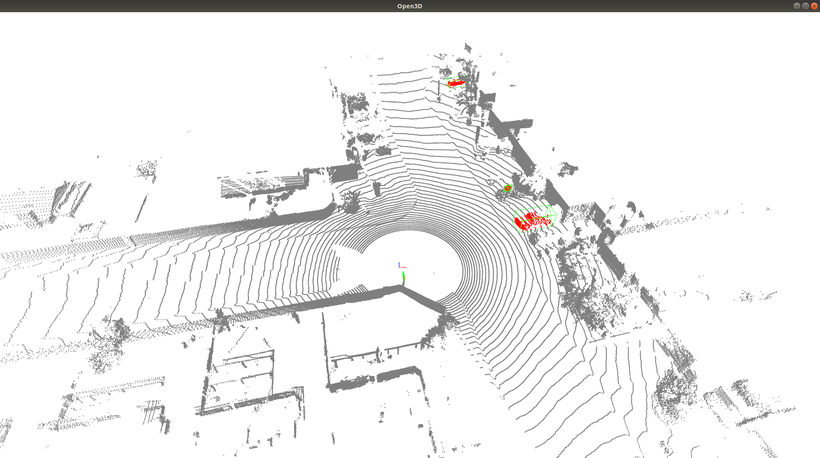
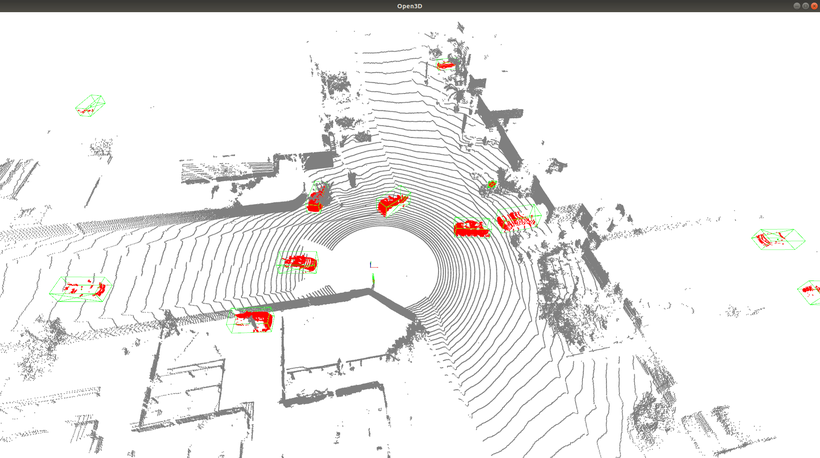
なお、AutowareではPose EstimatorとしてNDT scan matchingと呼ばれる手法を用いており、事前に用意した点群地図(下図:白色)と、自動運転車に搭載されたLiDARセンサーの観測点群データ(下図:赤や黄緑色)を比較して、パズルのように点群が最もうまく当てはまる場所を探し出して自己位置を計算しています。

このNDT scan matching単体でもかなり正確な自己位置を計算することができますが、LiDARのセンサーノイズや外環境の変化により絶えず数センチ程度のノイズが乗っています。ここにKFを導入することにより、推定精度をさらに向上させることが可能となります。
NDT scan matchingについての詳しい情報が知りたい方は過去の記事で述べていますので、こちらをご覧ください。前後編、二部構成の大作となっております。
さて、ここからはいよいよ本題の実装編に入っていきます。
いざ実際にカルマンフィルターを実装すると、特定環境で上手くノイズを除去できなかったり、推定値が一方向にズレる、といった問題が出てきます。
これらの問題の原因は、カルマンフィルターが想定している前提条件と実環境との差異を基準に議論することができます。
例えばカルマンフィルターは「センサーデータのノイズは白色ガウス分布である」といった仮定に基づいて最適化を行います。白色ガウス分布とは非常に理想的な形状をしているノイズなのですが、実環境でノイズがこのような理想形状をしていることは稀であり、自動運転においても例外ではありません。
センサーの遅延を例に見てみましょう。どんなセンサーにも遅延は存在しますが、通常のカルマンフィルターではセンサーデータに遅延が含まれることは想定していません。従って、特別な対処をせずにカルマンフィルターを適用すると、この遅延は白色ガウスノイズであるという仮定の下で処理されます。この仮定は実際のノイズ特性とは大きくかけ離れたものであり、推定精度の劣化に繋がります。
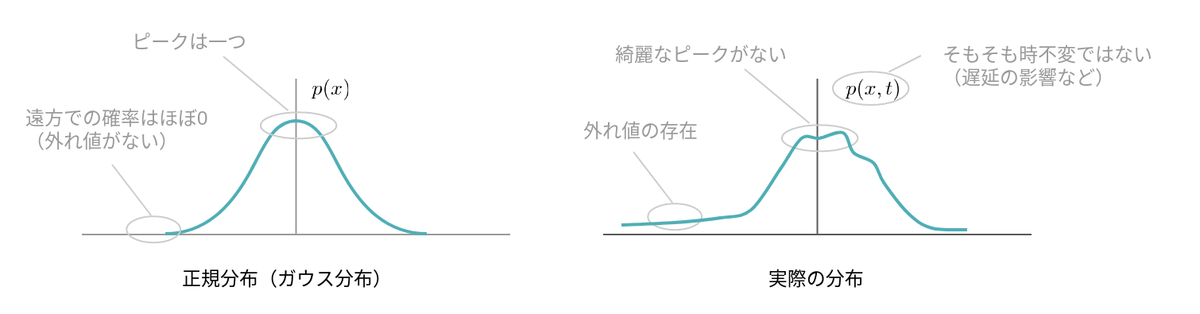
カルマンフィルターの想定する仮定を乱す要因は他にもあり、例えば
などです。これらの原因を見定め、1つずつ適切な対処をしていくと、仮定と現実の乖離が徐々に小さくなり、最終的な推定精度が向上していきます。
以下では代表的な問題と、その対応について解説します。
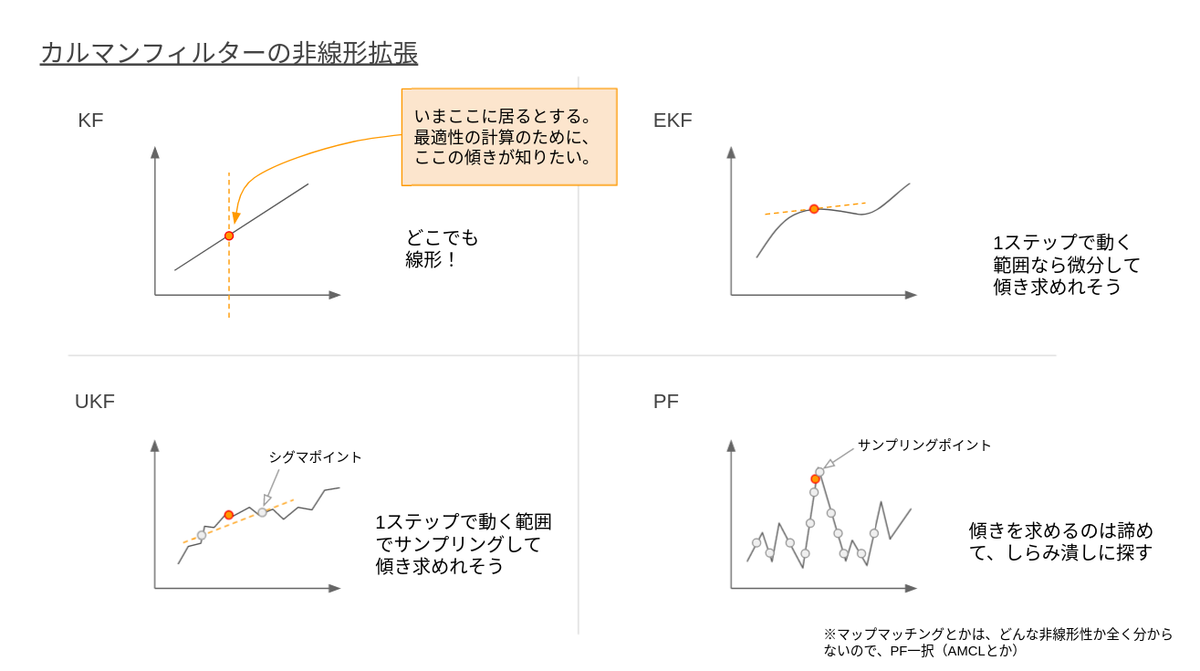
まずは非線形拡張についてです。ここはご存知の方も多いかと思います。
本来KFは線形モデルに対して理論が構築されたものでした。一方で車両の運動は非線形の数式で表されます。以下の式を見てみましょう。
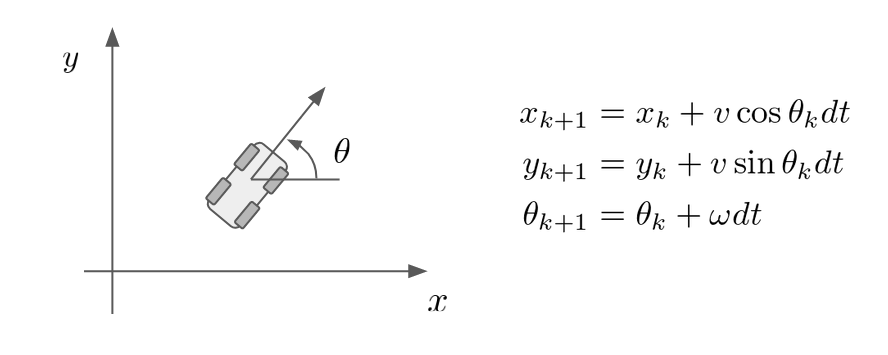
この式は車両が速度v、角速度ωで走行しているときの運動を簡易的に表現したものであり、上の二行の式によって「車両は自分が向いている方向に進む」ことを表しています。ここで問題になるのがsinとcosの存在です。彼らの存在によって式は非線形となってしまい、通常のKFでは対処できません。
この非線形への対処はすでに多くの方法が提案されています。有名なものではExtended Kalman Filter (EKF)、Unscented Kalman Filter (UKF)、Particle Filter (PF) などがあり、対象となる非線形性の強さなどに応じて利用するアルゴリズムを使い分けます。
これらのアルゴリズムは非線形性への対応度と調整・計算コストのトレードオフとなっています。例えば、最も柔軟に非線形に対応できるParticle Filterと呼ばれるアルゴリズムは、一方で非常に計算コストが高く、出力結果にランダム性が生じるといった課題もあり、モデルの非線形特性を適切に理解した上でアルゴリズムを選定する必要があります。
Autowareでは現在はEKFと呼ばれる手法を用いて非線形モデルに対応しています。
センサーには必ず遅延が存在します。例えばティアフォーで利用している回転式のLiDARは100msかけて360度のスキャンを行うため、平均50msの遅延が存在します。また、KFの前段のNDTによる計算処理も数10msの時間を要します。
数10msと言われると誤差のようにも聞こえますが、高速で移動する自動運転においてこの遅延は致命的であり、例えば時速60kmで走行中に自己位置推定に100msの遅延が生じたとすると、それだけで約1.7mの誤差を生み出します。
AutowareではAugmented State Kalman Filterと呼ばれる手法を用いて遅延補償を行っています。これはKFの状態を時間方向に拡張し、「過去の状態」を陽に考慮することによって遅延に対応する手法であり、これによって遅延を含んだ情報を、拡張された次元の一部が遅延無しで観測されたとみなすことができます。

詳しくはこちらの書籍 *2 にまとめられています。
(こちらは1979年の論文集なのですが、遅延よりも先にデジタル処理による離散化の影響と補償法について述べられています。当時は計算機の処理が遅く、KFの処理自体に時間がかかっていたのでしょう。こういった時代背景も踏まえて論文を読むといろいろな発見があって面白いですね。)

さて、KFを使って遅延に対処する方法が分かりました。しかし、肝心の遅延時間はどのように測定するのでしょうか。
センサーが観測をした真の時間を知る必要があるのですが、ここでもいくつか問題が生じます。それが時刻同期やタイミング同期です。
時刻同期はイメージしやすいと思います。センサーが観測した時刻を知るためには、センサーの時刻ソースと自動運転システムの時刻ソースを揃えたり、観測〜データ受信までの遅延を事前計測しておく必要があります(センサ側でタイムスタンプが得られる場合は前者、出来ない場合は後者)。自動運転には多くの計算機が搭載されており、それぞれの時刻を全て同期させる必要があります。
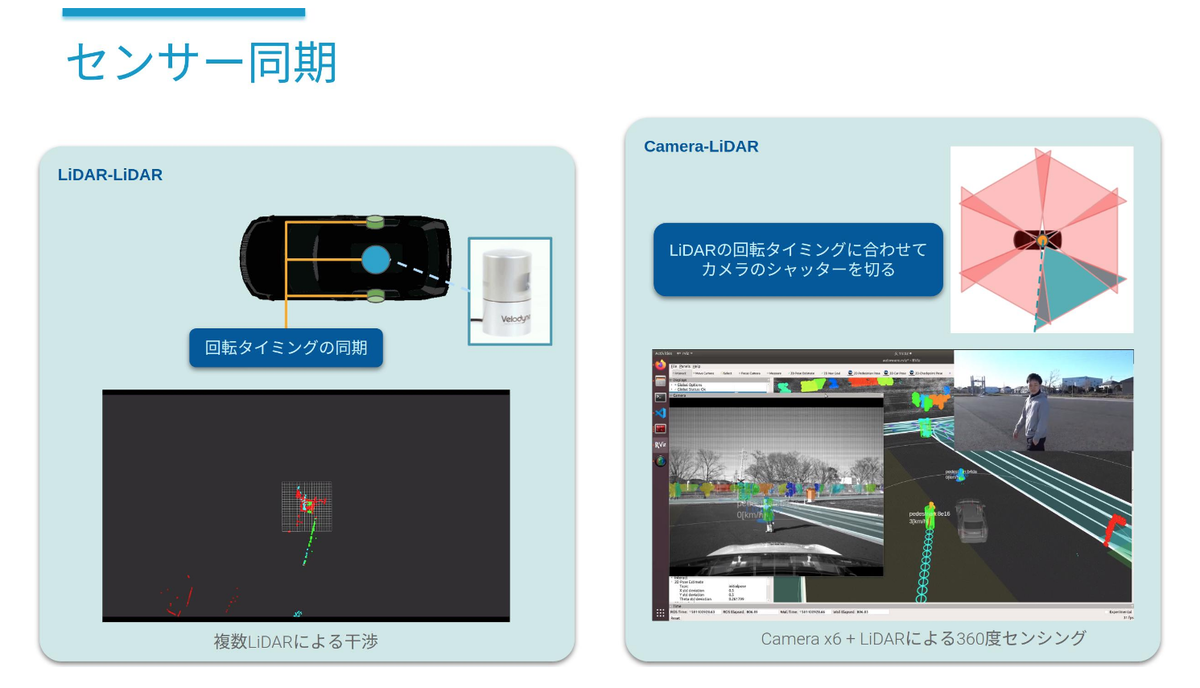
タイミング同期は、複数センサーの観測タイミングを制御する仕組みです。Autowareでは複数のLiDARデータから得られた情報を結合し、一つの大きなデータとして処理します。このときそれぞれのLiDARが異なるタイミングでスキャンを実行していては、空間的なズレが生じてしまい適切な結合が出来ません。そこで、全てのLiDARの動作タイミングを同期し、仮想的に一つの大きなLiDARが回転しているように振る舞わせることによってこの問題に対処しています。
また、このセンサー同期には他にもいくつかの目的があり、LiDAR同士の干渉問題の解決や、動物体検出におけるLiDAR-カメラフュージョンの性能向上にも一役買っています(下図参照)。
これはこれで話が広がる部分ですが、また次の機会に。
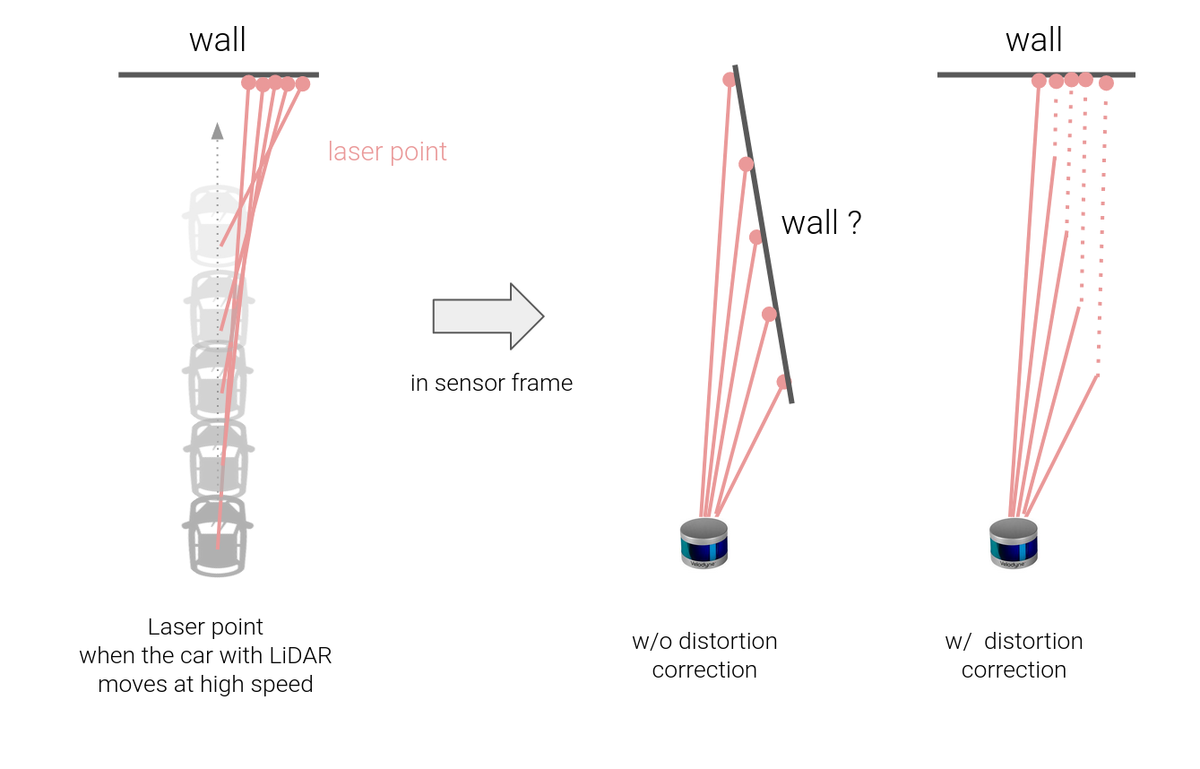
時間方向の点群の歪みも問題になります。
LiDARの「一定時間かけてデータを取得する」という特性上、データ取得の開始・終了時点で車両位置が違う、という問題が出てきます。このため、LiDARの生データをそのまま「特定の時刻の情報」として扱うことはできません。
これはカーブ走行時などに特に顕著に現れ、低速走行においても大きな測定誤差を生じます。
この問題を解決するため、AutowareではLiDARの取得点群一つ一つに時刻を埋め込み、その時の車速・角速度情報を用いて点群に時刻補正を掛けるという対応を行っています。
これによって自車の移動に依存しない安定した点群を取得することが可能となり、自己位置推定の精度が大幅に向上します。
次は車両モデルの誤差についての話です。例として、LiDARセンサーの取り付け角度がズレている場合を考えてみます。
NDT scan matchingはセンサーによって得られた点群によって自己位置を推定しますが、あくまでも推定できるのはセンサーの位置姿勢であり、センサーと車両の位置関係は事前に与える必要があります。
この位置関係が間違っているとどうなるでしょうか。
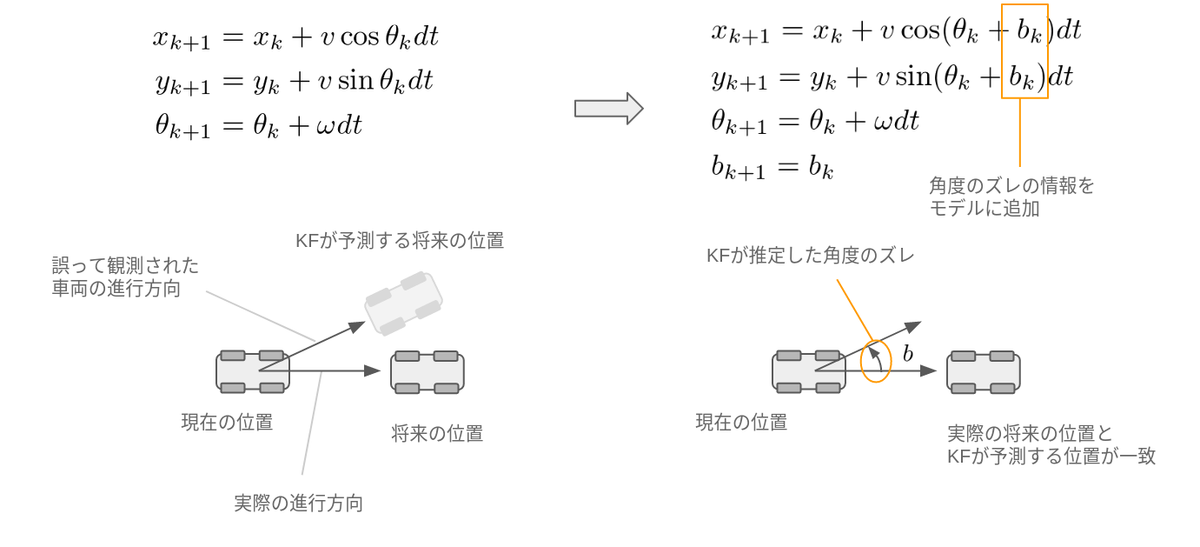
例えば下図のように、実際の車両は右に向かって走行していますが、センサーが誤って斜め上の方向に向かって取り付けられており、車両の向きを間違って推定してしまったとします。すると、KFが推定する位置と実際の位置に乖離が生じます。これはKFから見るとノイズの一種なのですが、常に特定方向に偏ったノイズが与えられてしまい、これは事前に説明した白色ガウスノイズの仮定から逸れてしまいます。結果、常に推定結果が横に逸れた状態で計算されます。
これは適応オブザーバー(外乱オブザーバー)と呼ばれる方法を用いて解決されます。
適応オブザーバーとは、KFのモデルに「センサーの取り付け角度がズレる可能性があるよ」という情報を付加することによって、走行中にこのズレを自動で推定する手法です。
実際には、このセンサーの取り付け誤差は走行前のセンサーキャリブレーションによって取り除かれます。
一方で、どうしても事前に取り除けない誤差、例えば温度変化によるヨーレートセンサーのバイアス項や、空気圧変化によるタイヤ径の変化、路面環境の変化などは、このように動的な補償によって対処する必要があります。
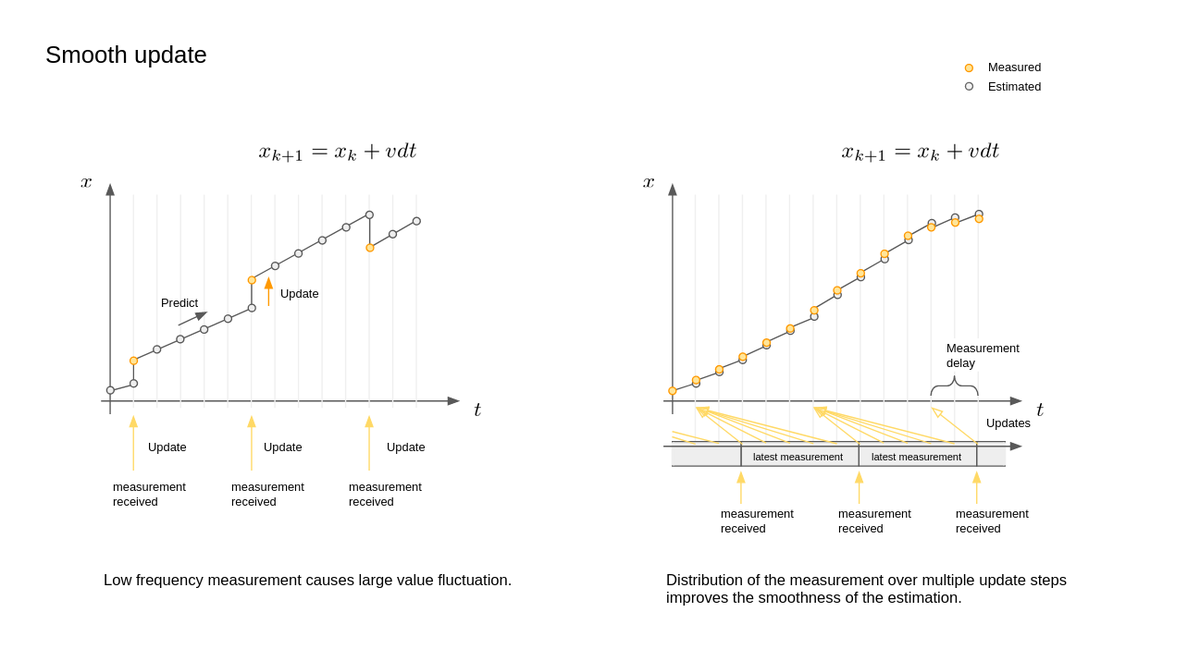
複数のセンサー情報を統合するKFの技術は、センサーフュージョンと呼ばれることもあります。ここで問題になるのがセンサーごとの周期の違いです。
例えば、IMUのような内界センサーは数100~数1000Hzで情報を出力することができる一方、NDT scan matchingのような外界センサーに依存した手法は(現在は)10~20Hzでしか情報を出力できません。これらのセンサー周期の違いを考慮せずに統合してしまうと、低周期のセンサー情報がKFに統合されたときに大きく自己位置が変化する、という現象が発生します(下図:左側)。
この「大きな自己位置の変化」自体はKFとしては正常な動作であり、その瞬間にもっとも信頼度の高い位置を出力しているだけに過ぎません。それに対して、この自己位置を車両制御で用いる際には、自己位置のズレがステアの振動に直結するため問題が生じます。
AutowareのKFでは、自己位置の変動に大きな影響を及ぼす情報が得られた場合は、その入力を時間方向に分散させて更新を掛けることによって、滑らかな自己位置の遷移を行っています(下図:右側)。
これは、遅延補償機能との合わせ技であり、遅れて更新を掛けても適切に処理可能であるという前提に基づいています。
続いて、センサーの外れ値対応についてです。
例えばGPSのキッドナップ問題と呼ばれる有名な課題があり、GPS信号のマルチパスなどによって、急にGPSの位置が大きくズレることがあります。NDTも同じく、アルゴリズムが収束しなかった場合などは推定値が大きく真値から外れます。
KFはガウスノイズを仮定しているという性質上、外れ値に大きく引きずられるという特徴があり、これらの外れ値は別途対応する必要があります。
Autowareではこの外れ値判定に2つのゲートを設けて対応しています。
まず、NDT側でイテレーション回数などの内部情報を元に外れ値・アルゴリズムの失敗を検出し、計算結果がおかしい場合は結果を出力しないという方針を取っています。これは基本的にワンショットの情報(これまでの時系列の統計情報を含まない情報)で判断されます。
その後段で、KFによって時系列情報を用いた外れ値判定(マハラノビスゲート)を適用します。KFでは推定結果の信頼度(誤差共分散)を内部情報として蓄えており、この情報を元に、KFへの入力がどれだけ確からしいのかを計算することができます。
例えば、これまでの入力の信頼度が低く十分な推定ができていない場合に、実は自己位置の場所が大きく異なっていましたと言われたら、その値は考慮すべきです。一方で、すでに十分な推定精度が得られている場合は、たとえ外部情報が自信満々に値を出してきたとしても、それがあり得ない確率であればその入力を棄却する必要があります。この外れ値の計算にはマハラノビス距離と呼ばれる、入力ベクトルの距離を共分散行列で正規化した値が用いられており、確率論ベースで情報の統合・棄却を判定します。

上節で、共分散行列を元に推定値の信頼度を計算するという話をしました。この「信頼度が計算できる」というKFの機能は非常に有用であり、自動運転の安全性に大きく影響します。
例えば、自己位置の推定精度が悪い場合はレーンからはみ出てしまう可能性があるため、速度を落として走行したり、停止することが求められます。
しかし、この信頼度を正確に計算するためには、KFで統合される信号のノイズ情報が正しく設定されている必要があり、「運動モデルがどの程度正しいのか」「どのくらいのズレがあるのか」「観測値の誤差はどのようなノイズ特性を持つのか」などを一つ一つ検証する必要があります。
このノイズ情報の設定はなかなかに骨の折れる作業で、"How To NOT Make the Extended Kalman Filter Fail" *3という論文で取り扱われるほど多くのエンジニアを悩ませてきた問題です。
例えばIMUのヨーレートセンサーのノイズです。まずは真値と比較を行い、ノイズ情報(二次モーメント)を計算します。このときのノイズ特性が、どれだけKFの仮定(白色ガウス)とズレているのか、が大きなポイントとなります。ヨーレートセンサーは一般的にバイアスノイズの影響が大きいため、まずはこのノイズを除去する必要があります。
その他のセンサーや運動モデルにおいても、どうやったら白色ガウス分布からのズレを除去できるのか、除去できない場合はワーストケースを考慮すると共分散はどう設定すべきなのか、などを検討する必要があります。

ここまでKFの拡張や精度、外れ値対応などについて述べてきました。しかし、自動運転において「外れ値が来たので無視します」という処理だけでは安全性を担保することができません。
ここでAutowareのLocalizationモジュールを再見すると、Localizer Diagnosticsというモジュールが存在していることが分かります。
このモジュールはAutowareの自己位置推定の機能群を常に監視しており、外れ値が計算された、位置推定の精度が落ちた、などの情報を統合して現在の自己位置推定の状態を判断します。
この診断情報は別のSystemモジュールへ送られ、状態に応じて適切な指示が車両に送られます。例えば、LiDARに依存した自己位置推定アルゴリズムが何らかの異常によって再起不能になった場合でも、内界センサー(車速センサーやIMU)による自己位置推定によってしばらくは走行が可能であり、自己位置の推定誤差が閾値を超過する前に適切な駐車場所を見つけ、路肩に停車するといった動作が可能となります。
最後まで読んでいただきありがとうございました。
このブログで述べた機能は、いくつか開発途中のものもありますが、大半はOSS(Open Source Software)として利用可能となっています。興味があればぜひ御一見ください。
いろいろと機能の説明をしてきましたが、自動運転技術は発展途上であり、まだまだ開発が必要な領域が残っています。
このブログを読んで、自動運転って面白そう...!と思った方がいましたら、ぜひ一緒に開発をしましょう!下記リンクからお問い合わせをお待ちしています。
*1:Kalman, R. E. (March 1, 1960). "A New Approach to Linear Filtering and Prediction Problems." ASME. J. Basic Eng. March 1960; 82(1): 35–45.
*2:Anderson, B. D. O., & Moore, J. B. (1979). Optimal Filtering. Englewood Cliffs, NJ: Prentice-Hall.
*3:René Schneider and Christos Georgakis. "How To NOT Make the Extended Kalman Filter Fail." Industrial & Engineering Chemistry Research 2013 52 (9), 3354–3362.
こんにちは、ティアフォーでVisual SLAMの研究開発をしている石田です。今回はVisual-Inertial Odometryという、カメラとIMU(慣性計測装置)を用いた経路推定手法を紹介し、これを自動運転に応用できた場合のインパクトと、応用までに乗り越えなければならない課題についてお話します。


なお、ティアフォーでは、「自動運転の民主化」をともに実現していく様々なエンジニア・リサーチャーを募集しています。もしご興味があればカジュアル面談も可能ですので以下のページからコンタクトいただければと思います。
自己位置推定とは、名前のとおり車両やセンサーデバイスなどが地図の中でどこにいるのかを推定するための技術であり、自動運転において欠かせない要素のひとつです。自分がどこを走っているか把握できなければ迷子になってしまいますし、自分が走っている場所の先に何があるか把握することも難しくなってしまいます。正確な自己位置推定が実現できれば、車両のスムーズな制御につなげることができて、さらに信号機や標識、停止線などの場所をあらかじめ地図に埋め込んでおき、車両がこれらに近づいたことを正確に検知できれば、安全かつ確実な制御を行うことができます。
自己位置推定の課題は大きく分けて3つあります。1つ目は精度、2つ目はロバスト性、そして3つ目はこれらを小さい計算量で達成することです。
公道を走る車両の自己位置推定は少なくとも数十センチの精度が要求されます。この精度を達成できないと、走行レーンをはみ出したり他車にぶつかったりしてしまいます。
自動車は様々な環境や場所を走るため、自動運転車に搭載される自己位置推定システムも正確な動作が必要となります。市街地も森も田園も橋の上も安全に走れる必要がありますし、雨や雪が降っていても正確に動作する必要があります。このように様々な場所や環境で動作する能力は「ロバスト性」と呼ばれ、精度と同様に自己位置推定手法における重要な指標とされています。
計算量を抑えることも重要な課題のひとつです。自分の位置を計算するのに1秒かかっていたら、その間に車が動いてしまい、周囲の物体にぶつかってしまいます。しかし、計算を高速化させたいからといって車に巨大なコンピュータを積むと、車両の価格が上がったり、膨大なエネルギーを消費したり、コンピュータの周囲が高温になってしまいます。このため、自動運転のための自己位置推定手法は小さいコンピュータでも高速に動作しなければなりません。
高精度で、ロバストで、ライトな自己位置推定を実現する。これが我々の仕事です。
自己位置推定を実現するためのセンサーには様々なものが存在します。皆さんにとって最も身近なものは、おそらくスマートフォンやカーナビに搭載されているGPSでしょう。しかし、皆さんもご存知のようにGPSは屋内などではうまく動作できないうえ、自動運転に使えるほどの精度が常に実現できるわけではありません。
現在のティアフォーの自動運転車は主にLiDARというセンサーを用いています。LiDARはレーザー光によって周囲の形状を把握するセンサーで、LiDARによって得られた車両の周囲の形状と、あらかじめ作成しておいた点群地図を照合することで、車両の位置を高い精度で推定することができます。しかし、LiDARにも弱点があります。LiDARを用いた自己位置推定手法は主に周囲の環境の構造情報を頼りにしているため、特徴的な構造が観測しづらい場所、たとえば田園などではうまく動作できません。また、性能のよいLiDARは非常に高価で数千万円もしてしまうため、これをそのまま自動運転車に用いると、車両も同様に高価になり自動運転車の普及の妨げになってしまいます。したがって、自動運転の実用化および普及促進のためには、LiDARだけに頼るのではなく複数の安価なセンサーを組み合わせることが不可欠です。
ここで今回私が紹介するVisual-Inertial Odometryの出番です。Visual-Inertial Odometry(VIO)とは、カメラとIMU(慣性計測装置)を使って移動経路を求める手法です。
カメラはスマートフォンにも搭載されていますし、昨今のリモートワークでお世話になっている方も多いでしょう。もしかしたら毎日使っている方もいるかもしれません。IMUもカメラと同様に多くのスマートフォンに搭載されているのですが、こちらは馴染みのない方もいらっしゃるかと思います。IMUは人間における三半規管のようなもので、加速度と回転速度を計測することができるセンサーです。皆さんは車やバスに乗っているとき、目を閉じても車が加速しているのか減速しているのか、右に曲がっているのか左に曲がっているのかを、大まかに感じ取ることができると思います。IMUもこれと似ていて、物体の加速度や回転速度を計測することができ、この情報をもとにしてセンサーがどの方向にどれぐらい動いたかを大まかに計算することができます。これらのセンサーから得られる情報を組み合わせて移動経路を推定するのがVisual-Inertial Odometryです。

VIOに用いられるセンサーの一例。画像中央にある小型の横長のものがカメラとIMUが一体になったもの。画像で示されているのは検証用のものであり、実際の制御に用いられているものではない。画像左上に見えている筒状のものがLiDARであり、こちらは形状ベースの位置推定に利用される。
カメラやIMUはほとんどのスマートフォンに搭載されている非常にありふれたセンサーです。自動運転車に利用するためにはより高信頼なものが必要になるものの、それでも数万円から数十万円で調達することができます。VIOはLiDARベースの手法と比べるとまだまだ精度やロバスト性の点で劣るため、いますぐLiDARに置き換えられるというものではありません。しかし、カメラやIMUから得られた情報を組み合わせれば、同じ性能の自己位置推定をより安価なLiDARで実現できる可能性があります。結果として、車両全体の価格を押し下げることができ、自動運転の迅速な普及に貢献することができます。
VIOはすでに多くの研究がなされており、様々な手法が存在します。今回紹介するのは、現在私が性能検証を行っている、VINS-FusionというVIOの手法です。VINS-Fusionを選定した理由として、VIOの手法の中では精度が高いこと、他のセンサーと組み合わせやすいこと、計算量を抑える仕組みが導入されていることが挙げられます。ここでは、VINS-Fusionの手法の特徴を大まかに解説し、安心安全な自動運転を実現するために必要な研究と今後の開発についてお話します。
VINS-Fusionは、センサーの観測値を用いてあるエラー値を算出し、それをできるだけ小さくするようなセンサーの姿勢を求めることで、センサーの移動経路を推定します。たとえば、ある静止した物体を見ているとき、カメラが近くにいるならその物体は大きく見えますし、カメラが遠くにいるなら小さく見えるはずです。カメラが遠ざかっているのにその物体がだんだん大きく見えるようになるのはおかしいですよね。IMUについても同様で、IMUに対して加速度が前にかかっているなら、IMUは前に進んでいるはずです。加速度が前にかかっているのに、IMUが後ろに進んでいるなら、これもやはりおかしいです。この「おかしさ」を数値にし、それができるだけ小さくなるようなセンサー姿勢を求めるのがVINS-Fusionのアプローチです。物体が徐々に大きく見えるようになっているとき、「カメラが物体に近づいている」と推論すればこの「おかしさ」の数値は減っていきます。同様に、IMUが前向きの加速度を検知しているとき、「IMUは前に進んでいる」と推論すればやはりこの「おかしさ」の数値は減っていきます。このように、物理現象とつじつまが合うように「おかしさ」の数値を設計し、それが減るようなセンサーの姿勢を求めるのがVINS-Fusionの戦略です。
1. IMU積分値近似
VINS-Fusionのアプローチは、先ほどの「おかしさ」を徐々に減らしながらセンサーの姿勢を調節するため、一般に計算コストが高いとされています。この問題を解決するため、VINS-Fusionにはこの「おかしさ」を高速に計算するためのIMU積分値近似という仕組みが備わっています。
IMUで観測された加速度や回転速度はしばしば実際の値よりも少し大きく、あるいは小さく出力されます。これはIMUの特性上どうしても起きてしまうもので、VIOの開発者たちはがんばってこのズレを補正することで、実際の値にできるだけ近い観測値を得ようとします。
観測値と実際の値のズレは先ほどの「おかしさ」を計算するときに問題になります。「おかしさ」を計算するためにはIMUの観測値を積分して、IMUが進んだ距離を計算する必要があります。たとえば、「今はIMUから1.0という加速度が観測されているから、1秒間に8.0cm進んでいるはずだ。でも姿勢推定システムは1秒間に6.0cm進んでいると考えているから、おかしさは2.0cmだな!」というふうに考えるわけです。しかし、観測値のズレを補正するということは、距離計算の入力値(加速度や回転速度、先ほどの例だと1.0という数字)が変わることに相当するので、観測値の補正を行うたびに進んだ距離の計算をやり直さなければならなくなってしまいます。「さっきは加速度1.0で計算したけど本当は1.2なの?じゃあ今何cm進んでいるんだろう...」という計算を何度も何度も繰り返さなければならなくなってしまうのです。冒頭で述べたように、VIOは小さい計算コストで高速に動作することが求められるので、この計算に時間を取られてしまうと実用化の大きな支障になります。そこでVINS-Fusionは、この計算を近似的に行うことで処理の高速化を図っています。たとえば、「加速度を+0.1補正したら進む距離が0.4cm増える。ならば、加速度を+0.2補正したら進む距離は0.8cm増えるだろう」というように、非常に大まかに、しかし高速に計算を行います。これにより、姿勢推定全体を高速化することができます。
2. キーフレーム選択
動画撮影用のカメラは1秒間に何枚ものフレームを撮影することができます。たとえばiPhoneのビデオ機能は1秒間に30フレーム撮影しているそうです。では1秒間に30回撮影されるフレームそれぞれについて、位置や姿勢を推定する必要があるでしょうか。カメラが高速に移動していれば、たしかにそうかもしれません。では、静止している場合はどうでしょうか。静止しているなら、1秒間に30回も姿勢推定を行う必要はありませんね。VINS-Fusionをはじめ、多くのVIOには、キーフレーム選択と呼ばれる「大きく動いたときにだけフレームの姿勢を推定する」という機能が備わっています。このように、必要なときのみ姿勢推定を行うことで実行速度を上げることができます。また、余った計算コストを必要な部分に振り分けることで、精度も高められるというわけです。
最後に、VIOの今後の課題と将来性についてお話して、記事の締めくくりとします。
VIOはまだまだ発展途上の技術であり、精度やロバスト性はLiDARベースの自己位置推定手法におよびません。しかし、VIOをLiDARベースの手法と組み合わせることで、お互いの弱点を補いあい、強みを活かすことができます。たとえば、VIOはカメラ画像を入力とするため、対向車のヘッドライトのような大きな照度変化に影響されやすいという弱点があります。一方でLiDARはレーザー光で周囲の形状を把握するセンサーなので、明るさの変化の影響をほとんど受けないという特性があります。したがって、VIOとLiDARを組み合わせることで、様々な環境で安定して動作する自己位置推定システムを作ることができます。現在私はこういったセンサーの組み合わせに取り組み始めているところです。
霧や大雨の中では、人間でさえ安全な運転が難しいと感じることがあり、これは皆さんも経験したことがあるかもしれません。同様に、自己位置推定の手法も環境によっては確実に動作できないことが考えられます。こういったときに無理に自己位置推定を行って危険な走行をするのではなく、「動かない!」と言って停止することも自動運転車の大事な機能です。VIOはまだまだ普通の環境でしっかり動くことを目指す段階なので、このような停止判断機能はもう少し先の話になりますが、高信頼な自動運転を実現するためにはいずれ取り組まなければならない課題です。
Visual-Inertial OdometryはAR(Augmented Reality、拡張現実)などではすでに実用化されているものの、自動運転に応用するためにはまだまだ多くのハードルを乗り越えなければなりません。様々な環境で正確かつ高速に、しかも高信頼に動作する自己位置推定手法を開発するのは、非常にチャレンジングでワクワクするものです。もしこのような仕事にご興味ある方がいましたら、改めてにはなりますが、以下のページからご応募ください!!