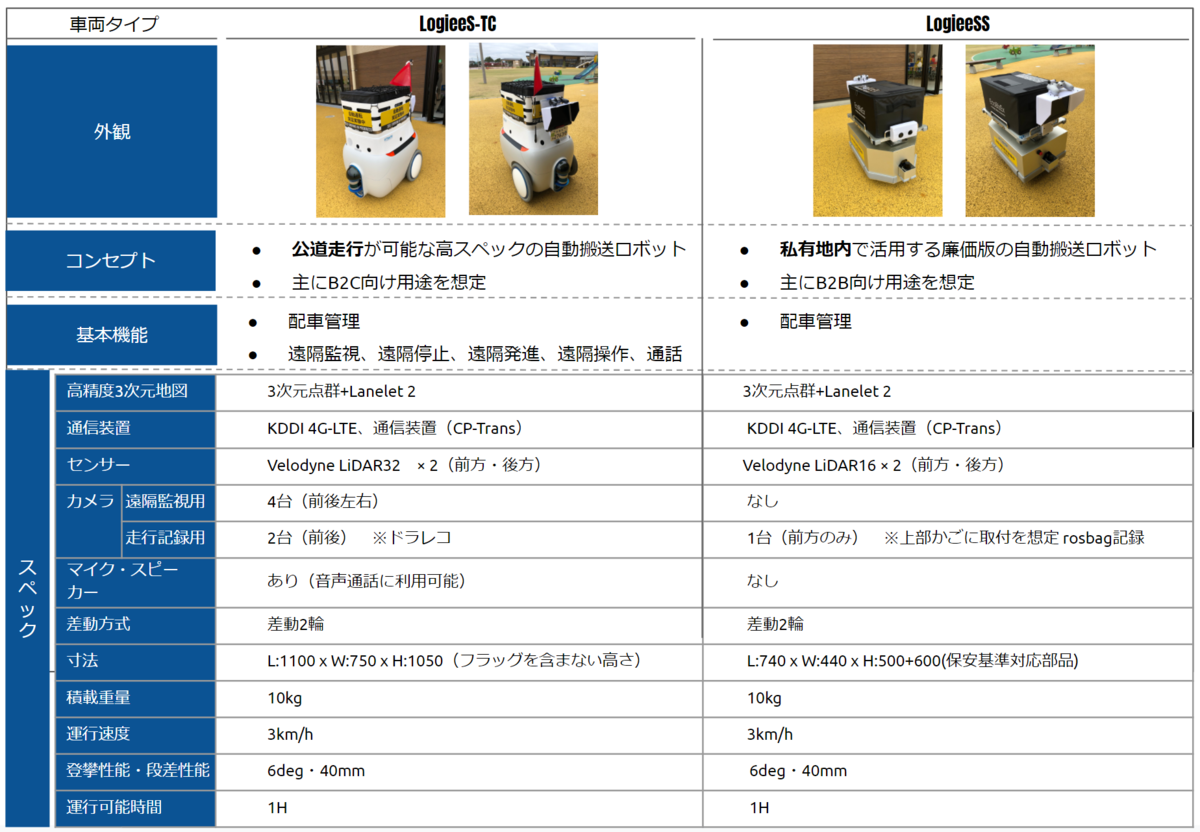
こんにちは、ティアフォーパートタイムエンジニアの上野と、ティアフォーエンジニアの村上です。
今回読み解いたのは、自動運転位置推定のターニングポイントとなった、Scan Matchingによる高精度自己位置推定技術の華、NDT Scan Matchingです。点と点のMatchingから、点と分布のMatchingにすることで、計算負荷が現実的な程度まで削減されました。方法としては博士論文 M. Magnusson, “The three-dimensional normal-distributions transform : an efficient representation for registration, surface analysis, and loop detection,” PhD dissertation, Örebro universitet, Örebro, 2009. で説かれており、また論文中の方程式は、Autowareの実装コードの中でも度々言及されています。
しかしながら、LiDARを使用した高精度な位置推定に今や必須となったこの方法は、なおも計算負荷が比較的高いままです。 計算負荷の観点でも目にする機会が多いこのアルゴリズムを、定量的/実装的な観点からあらためて見てみましょう。
NDT Scan Matcherについて、Autowareが用いている実装としては、全体的には ndt_scan_matcher_core.cpp 、部分的には ndt_omp_impl.hpp に主要な処理が記述されています。
主要な処理は、その負荷の大きさや計算の姿から大きくは、1. 移動がある自動運転におけるMatchingスコア値収束性能向上のための「近傍地図点群の取得処理」と、2. LiDAR点群と近傍地図点群のDistributionを用いた「Matchingスコア値計算処理」との2つの処理に大別されます。
以下にndt scan matcherのflame-graph画像を上げます。初期位置/姿勢の推定処理である alignUsingMonteCarlo 部分を除外し callbackSensorPoints 直下に注目します。
ndt scan matcher; flame graph
KdTreeFLANN::radiusSearch が1. 近傍地図点群の取得の部分で、これが大体40%近い処理量となります。その他の computeDerivatives がおおよそ2. Matchingスコア値の計算をしている、演算中心の部分です。
前半の今回は、まず入力として入ってきたLiDAR点それぞれに対し、物理的に近傍な地図点群を取得する方法を詳しく見ていきたいと思います。
Radius Search on KD-Tree 近傍地図点群(のvoxel)を取得する方法には、木探索による方法と、位置をkeyとしたhashからvoxel(とその上下左右前後にあるvoxel)を直ちに求める方法の、大きく2種類があります。
ここで取得される近傍voxelの数は、続く演算処理量を線形に増加させることに注意します。代表的な関数だけを抽出すると、以下の図のような関係となります。
木探索は近傍判定を精密にし、それ自体の処理量は重いですが、結果として近傍数が減少傾向となります。対してhash引きは、近傍判定を等閑にするため軽く、結果として近傍数が増加傾向となり、Scan Matching全体の処理量は増加する可能性があります。下のグラフにもこのことは表れています。
Radius Search(木探索)の場合のLiDAR InputsとNeighbor Voxelsの関係
(縦: 個数, 横: LiDAR frame)
HASH引き(周辺26voxel)の場合のLiDAR InputsとNeighbor Voxelsの関係
(縦: 個数, 横: LiDAR frame)
近傍の多寡による処理量のトレードオフとともに、”近さ”の正確さは、位置推定精度にも大きく関わるため、判定方法の選択にはこれらを総合的に勘案して採用することになります。Autowareを使用する際のTuning対象として、様々な近傍探索の実装例や実証実験での採用例があります。
ティアフォーでは表題の通りKD木(K-Dimensions tree)上でのRadius Searchを使用しており、今回はこの探索を見ていきたいと思います。
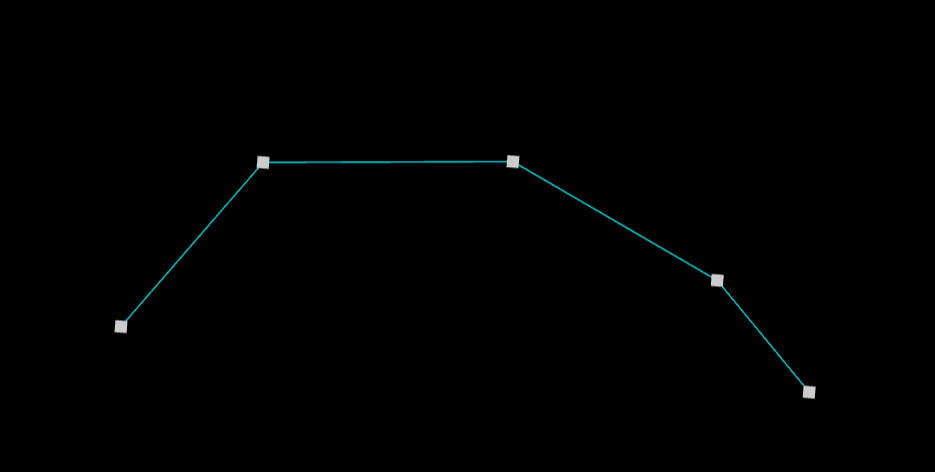
地図のKD木の構築方法 KD木とは多次元(K-Dimensions)空間を分割して作る二分木です。KD木の構築は、多次元空間を各座標軸に垂直に分割していくことで行われます。KD木の各ノードは多次元空間の部分空間に対応しており、あるノードの子ノードに対応する空間は、親ノードの空間に包含されるという関係にあります。
以下、地図点群からKD木を構築する方法について、具体的に説明します。なお、簡単にするために2次元を例として用いますが、実際にAutowareで用いられている地図は3次元であることは留意してください。また、空間の分割はX軸 → Y軸 → X軸 → … と交互に行われることとします。
{(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)}という6つの点から成る点群から構築する手順を以下のGIFで示します。
まず最初に、全体の空間をX軸で2分割するにあたって、点群全体をX軸の値でソートし中央の点 (7, 2)を中心とし、全体を分割します。この時の中心が木のルートノードとなります。
続いて、ルートノードから見て左側の子ノードを構築します。2段目ではY軸の値でソートし、中央となる(5, 4)を中心に2分割します。ルートノードから見て左側の構築が葉まで完了したら、最後に右側の子ノードを構築していきます。
このようにKD木を構築すると、この2次元空間は下図のような領域に分割されることになります。
Radius Search 次に、上で構築した木構造に対してクエリ点(入力点)を与え、Radius Searchを行う方法について説明します。 例として、点(6, 1)から半径2以内の距離にあるノードを、Radius Searchで取得します。
アニメーションの通り、深さ優先探索となります。近傍点の判定は、木を降りていく途中で各ノードに対応する分割点と与えられた点との距離を比較し、所与の半径以内であるか否かで行います。
まず最初に、ルートノードの分割点とクエリ点のX軸の値を比較します。今回は、クエリ点のX軸の値の方が小さいため、左側の子ノードに降りていきます。また、ルートノードの分割点 (7, 2) とクエリ点 (6, 1) の距離は2以下であるので、このノード(7, 2)自身も近傍として判定します。
次に、分割点とクエリ点のY軸の値を比べ、先と同様に、左右どちらの子ノードに降りるかを決定します。今回は(2, 3) のノードに降ります。さて、(5, 4)のノードとの距離は2より大なので、これは近傍点ではありません。また、(2, 3)のノードは葉ノードとなり、これ以上は探索しません。そして(2, 3)のノードもまた近傍点とは判定されません。
正確に近傍点を探すためには、木を降りるだけではなく「登る」処理が必要となります。葉ノードに到達した後、一度1つ上の(5, 4)のノードに登ります。そして、最初に探索しなかった側の子ノード以下に近傍点が存在するかどうかの判定を行います。
判定には、分割点 (5, 4) とクエリ点 (6, 1) のY軸の値の差の絶対値と探索半径との比較を用います。この時、探索半径の方が小さくなり、このことは (5, 4) のノードから見て右側の子ノード以下には近傍点が存在し得ないことを意味しますので、右側の子ノードに降りる必要はなく、探索は打切となります。
上の手順で降りた方向とは逆の枝を判定しつつ、木を順に登っていき、ルートノードまで登ってくることになります。ルートノードでも、最初に降りた方向とは逆、つまり例の場合右側の子ノード以下に近傍点が存在するか確かめましょう。ルートノードにおいて、分割点とクエリ点のX軸の値の差は探索半径よりも小さいので、右側の子ノード以下に近傍点が存在する可能性があります。よって、右側の子ノード側へも改めて降りていき、探索を行っていきます。
後は同様の手順を行い、結果として (7, 2) と (8, 1) の2点がクエリ点 (6, 1) の近傍として取得されます。
ただし、近傍探索の精度よりも高速性を重視する場合、葉ノードに到達した時点で近傍探索を打ち切る、すなわち「登る」処理を行わないことも考えられます。Autowareにおけるこの近傍探索はFLANN (Fast Library for Approximate Nearest Neighbors) というライブラリを用いていますが、このライブラリにおいても、実際「登る」側の処理は行われていません。
以下、OpenCLとして再実装を行いますが、同様の方針を取ることにします。
木構築とRadius Searchの再実装 この節ではKD木の構築を純粋なCとして再実装し、KD木を用いたRadius SearchをLiDAR点に対して並列化するためにOpenCLを用いて実装します。
LiDARの各点の処理や探索は、各点独立して並列に行うことができ、並列化のうまみが大きい部分です。また、KD木の構築も移植性やメモリ配置の透明性をもたせるため、Cとして再実装を行っています。
探索コード: https://github.com/yuteno/kdtree_radius_search_opencl
なお、KD木の構築はhttps://github.com/fj-th/kd-tree-C-language- のコードを参考にし、kdtree_construction.h に実装しています(元のコードは2次元平面上の点群の分割を行なっているため、これを3次元に拡張する形で変更しています)。
kdtree_node * kdtree(kdtree_node * root_node,
unsigned * alloc_pointer,
struct point * pointlist,
int left, int right, unsigned depth,
int * node_indexes) {
if (right < 0 ) {
return NULL ;
}
kdtree_node * new_node = &root_node[*alloc_pointer];
*alloc_pointer = *alloc_pointer + 1 ;
new_node->left_index = left;
new_node->right_index = left + right + 1 ;
new_node->depth = depth;
int median = right / 2 ;
if (right == 0 || depth > MAX_DEPTH) {
new_node->location = pointlist[median];
new_node->child1 = NULL ;
new_node->child2 = NULL ;
qsort(pointlist, right + 1 , sizeof (struct point), comparex);
new_node->leftmost = pointlist[0 ].x;
new_node->rightmost = pointlist[right].x;
qsort(pointlist, right + 1 , sizeof (struct point), comparey);
new_node->downmost = pointlist[0 ].y;
new_node->upmost = pointlist[right].y;
qsort(pointlist, right + 1 , sizeof (struct point), comparez);
new_node->zlowmost = pointlist[0 ].z;
new_node->zupmost = pointlist[right].z;
for (int i = 0 ; i < right+1 ; i++) {
node_indexes[new_node->left_index+i] = pointlist[i].id;
}
return new_node;
}
new_node->axis = depth % 3 ;
if (new_node->axis == XAxis) {
qsort(pointlist, right + 1 , sizeof (struct point), comparex);
new_node->leftmost = pointlist[0 ].x;
new_node->rightmost = pointlist[right].x;
} else if (new_node->axis == YAxis) {
qsort(pointlist, right + 1 , sizeof (struct point), comparey);
new_node->downmost = pointlist[0 ].y;
new_node->upmost = pointlist[right].y;
} else if (new_node->axis == ZAxis) {
qsort(pointlist, right + 1 , sizeof (struct point), comparez);
new_node->zlowmost = pointlist[0 ].z;
new_node->zupmost = pointlist[right].z;
}
node_indexes[new_node->left_index+median] = pointlist[median].id;
new_node->location = pointlist[median];
new_node->child2 = kdtree(root_node, alloc_pointer,
pointlist + median + 1 ,
left + median + 1 ,
right - (median + 1 ),
depth + 1 , node_indexes);
new_node->child1 = kdtree(root_node, alloc_pointer,
pointlist,
left,
median - 1 ,
depth + 1 , node_indexes);
上記コードは、KD木を構築したい点群の配列を pointlist として与え、再帰的に木構造を構築するコードです。L. 51 ~ L. 66 では、X, Y, Zのいずれかの軸で空間を分割します。pointlist を qsort でソートし、その中央を分割点としてノードを構築する部分は、前節で説明した通りです。ソートしたpointlist のうち、分割点よりもindexが小さい点群を左の子ノード(child1 )に渡し、分割点よりもindexの大きい点群が右の子ノード(child2 )に渡されます。また、node_indexes には点群のインデックスとノードのインデックスを対応させるのに必要な情報を格納します。
新たなノードを作る際に受け取った点群数が1であるか、または木の深さがMAX_DEPTH よりも大きくなれば、そのノードを葉ノードとして木の構築をそこで打ち切ります。この時、葉ノードであることは、child1 およびchild2 を NULL とすることで表現します。
また、root_node ポインタにはあらかじめ木のノード数分の領域を確保しておき、alloc_pointer を用いて、木のルートノードを先頭としてノードが構築された順にメモリ上に配置されるようにすることで、配置の透明性を上げています。
Radius SearchをOpenCLで実装した際のカーネルコードkernel_radius_search.cl を以下に示します。
__kernel void radiusSearchCL(const global float * lidar_points_x,
const global float * lidar_points_y,
const global float * lidar_points_z,
const global float * map_points_x,
const global float * map_points_y,
const global float * map_points_z,
const global int * node_indexes,
__constant kdtree_node * root_node,
const int n,
const int limit,
const float radius,
global int * neighbor_candidate_indexes,
global float * neighbor_candidate_dists) {
int item_index = get_global_id(0 );
if (item_index >= n)
return ;
float4 reference_point = (float4)(lidar_points_x[item_index],
lidar_points_y[item_index],
lidar_points_z[item_index],
0 );
if (item_index == 0 )
printf("ref point ( %f , %f , %d ), radius %f , limit %d\n " , lidar_points_x[item_index], lidar_points_y[item_index], lidar_points_z[item_index], radius, limit);
__constant kdtree_node *current_node = root_node;
int neighbors_count = 0 ;
int level = 0 ;
float dist;
float4 dist_square;
while (true ) {
if ((current_node->child1 == NULL ) && (current_node->child2 == NULL )) {
for (int i = current_node->left_index; i < current_node->right_index; ++i) {
int index = node_indexes[i];
float4 map_point = (float4)(map_points_x[index],
map_points_y[index],
map_points_z[index],
0 );
for (int d = 0 ; d < 4 ; d++) {
dist_square[d] = (map_point[d] - reference_point[d]) * (map_point[d] - reference_point[d]);
}
dist = sqrt(dist_square[0 ] + dist_square[1 ] + dist_square[2 ]);
if (dist < radius) {
neighbor_candidate_indexes[limit*item_index + neighbors_count] = index;
neighbor_candidate_dists[limit*item_index + neighbors_count] = dist;
neighbors_count++;
}
if (neighbors_count >= limit){
break ;
}
}
break ;
} else {
int index = node_indexes[current_node->left_index + (current_node->right_index - current_node->left_index-1 ) / 2 ];
float4 map_point = (float4)(map_points_x[index],
map_points_y[index],
map_points_z[index],
0.0f );
for (int d = 0 ; d < 4 ; d++) {
dist_square[d] = (map_point[d] - reference_point[d]) * (map_point[d] - reference_point[d]);
}
dist = sqrt(dist_square.x + dist_square.y + dist_square.z);
if (dist < radius) {
neighbor_candidate_indexes[limit*item_index + neighbors_count] = index;
neighbor_candidate_dists[limit*item_index + neighbors_count] = dist;
neighbors_count++;
}
if (neighbors_count >= limit){
break ;
}
float val = reference_point[current_node->axis];
float diff = val - current_node->axis_val;
__constant kdtree_node * next;
if (diff < 0 && current_node->child1) {
next = current_node->child1;
} else {
next = current_node->child2;
}
current_node = next;
}
}
}
OpenCLの各スレッドはitem_index を用いて入力点群のうちの1つを取得してクエリ点とし、構築したKD木に対して近傍探索を行います。
L. 35 からのwhile文で近傍探索を行ないます。
葉ノードに到達するまでは L. 60 からのelse節が実行され、ノードの分割点とクエリ点の距離を計算し、近傍点かどうかの判定を行いつつ適切な子ノードに向かって木を降りていきます。
葉ノードに到達すると L. 36 のif節が実行されます。葉ノードには分割点以外にも複数の点が含まれる場合があるので、それら全てとクエリ点の距離を計算し、近傍判定を行います。
また、前述の通り木を「登る」処理は行わないので、葉ノードに到達するか、あるいは取得した近傍点の数がlimit を超えた場合にwhile文からのbreakとなり、処理が終了します。
Host-Device間メモリについて KD木を用いたRadius Searchの処理を各点で並列化するためには、ホスト側で構築したKD木を各スレッドが参照できるメモリに配置する必要があります。そこで、__constant 修飾子を用いてコンスタントメモリに木構造を配置しますが、そのまま配置するとホスト側で、特に子ノードをポインタを使って表現されている木構造が、コンスタントメモリ上でも同様の構造を保つ保証がなくなってしまいます。
Fixstars社のTech blog でも詳しく紹介されています。また、OpenCLにおいてメモリ構造の記事は、こちらの記事 が大変参考になります。
AutowareのTutorial ROSBAGとMapを用いた動作 OpenCL実装したRadius Searchの動作確認を行うために、Autowareの動作確認に用いられているMapとLiDARのデータを使用します。しかし、LiDARのデータは、Autoware用のサンプルデータにおいてrosbagの中のtopic群として提供されていますし、何より座標変換の処理をしたり、複数のセンサーデータの統合もしなければなりません。動作確認だけのために、本実装にこの処理を追加するのは面倒なので、今回はAutowareを一部改変し、Scan Matching処理直前の点群を、外部ファイルに保存するという手段を取りましょう。
再びAutowareでの実装である、localization/pose_estimator/ndt_scan_matcher/ndt_scan_matcher/src/ndt_scan_matcher_core.cpp を見ていきます。
LiDAR点群が到着するたびに、コールバック関数 callbackSensorPoints が呼ばれ、それを入力としてScan Matching処理が行われます。そこで、この関数内で入力として使われている点群を外部ファイルに保存します。
先に座標変換の話に触れましたが、rosbagの中に存在するLiDAR点群の座標は、あくまでLiDARセンサから見たものであり、Map点群とのMatching処理入力として有効であるためには、車体およびMapに対して座標変換を行っておく必要があります。
ndt_scan_matcher_core.cpp の L.310 で setInputSource 関数を用いて sensor_points_baselinkTF_ptr という点群が入力として設定されていますが、この点群はまだ車体位置・姿勢に対しての座標変換が行われていません。車体位置・姿勢に対しての座標変換行列は、L. 346 で align 関数の引数として使われているinitial_pose_matrix です。そこで、PCL (Point Cloud Libary) の pcl::transformPointCloud 関数を用いて、sensor_points_baselikTF_ptr を initial_pose_matrx で座標変換を行います。このようにして変換した点群を pcl::io::savePCDFile 関数でpcdファイルに保存することで、Autoware用サンプルデータ内の点群を、今回の実装の入力として適当な形に変換することができます。
ぜひティアフォーへ! 今回の調査や再実装の動機は、採用できる計算システムの選択肢を広げたいところにあります。実証実験のソフトウェアは実証実験のシステムや環境からの影響を多大に受け、さらに使用しているライブラリ類の制限を多分に受けます。計算機側の立場は高速な開発/実証実験とは対極ではありますが、HW/SWの双方に高水準な性能が要求される自動運転開発の両軸です。
移植性についても、あらゆるシステムに移植できることは幻想です。ただ、特定のシステムに依存することは、本質的に効率の悪い選択肢をとらざるを得なければならない危険性を抱えてしまいます。
このようにティアフォーでは、自動運転技術の精度性能のチューニングはもちろん、計算システムでの性能のチューニングも行っております。計算機およびアルゴリズムは自信あり、でも自動運転は興味があるだけ...という、そこのお方!ぜひ一緒に完全自動運転を実現する計算機を探索しましょう!下記リンクからお問い合わせお待ちしています!
TIER IV Careers
tier4.jp

























 OpenCL 2.0から実装されたShared Virtual Memory (SVM) という機能を用いて上の問題を解決できます。名前の通り、ホストとデバイスで仮想メモリ空間を共有できる機能であり、今回の木構造のメモリのデバイス間共有に最適です。SVMについては
OpenCL 2.0から実装されたShared Virtual Memory (SVM) という機能を用いて上の問題を解決できます。名前の通り、ホストとデバイスで仮想メモリ空間を共有できる機能であり、今回の木構造のメモリのデバイス間共有に最適です。SVMについては