こんにちは、ティアフォーエンジニアの村上です。
今回は、 読み解くNDT Scan Matchingの計算 [前編] - Tier IV Tech Blog の続きとして、自動運転位置推定のターニングポイントとなった、Scan Matchingによる高精度自己位置推定技術の華、NDT Scan Matchingを読み解いてみようと思います。
まだの方は、前編もあわせてぜひご覧ください。
なお、ティアフォーでは、「自動運転の民主化」をともに実現していく様々なエンジニア・リサーチャーを募集しています。もしご興味があればカジュアル面談も可能ですので以下のページからコンタクトいただければと思います。
Scan Matchingのスコア計算へ
復習になりますが、LiDAR点(ここではSourceと呼びます)とMap点(ここではTargetと呼びます)との点と点のScan Matchingをそのまま考えると、その整合度合いを計算するために、O(N) * O(M) [where N = Source点数, M = Target点数]の計算量が必要となります。ここで、Target点群をいくつかの格子に分割後、"格子中の点群の正規分布"、つまり雰囲気のようなものへ変換してしまい、Sourceの各点がその分布上その位置に存在する確率を「スコア値」として考えてしまう発想に至ります。もはや分布となってしまったTargetは(当然分割格子数は実計算の多寡に影響するとはいえ)、定数扱いとなり、計算量はぐっと減少し、O(N)となります。また、雰囲気との比較というのは、局所最適解に陥りやすいマッチング処理において、ロバスト性を高める点にも一役買っています。
このTarget点群の正規分布化(Normal Distribution Transform)を用いた、Scan Matching処理こそがNDT Scan Matchingであり、今日の自動運転の高精度自己位置推定において大活躍しています。
前編において解説した、近傍Voxelの取得によって、Source各点に対するTarget中近傍Voxel(の"雰囲気")が取得されました。本編では、その取得された近傍に対して、Source点がたしかにそこにあるという"たしからしさ" = スコア値計算の部分を見ていきます。
OpenCL accelerated NDT Scan Matcher
前編でもOpenCLを用いた再実装を行いましたが、今回は前編の成果物もまとめ、NDT Scan MatcherをOpenCLで実装し、他のデバイス(もちろんCPUもです!)へ容易にオフロードできるパッケージを作成しました。以降コードリーディングの際にも折に触れて登場します。
OpenCL版のREADMEはこちらをご覧ください。
前項で述べた通り、NDT Scan Matchingにおいては、その内部の処理は、Source各点に対して、各点並列でスコアを計算していきます。最終的にはそのSource各点のスコア値は合算されますが、この処理は並列化が比較的容易なアルゴリズムとなっており、AutowareではOpenMPによる並列化実装が採用されています。
OpenCLでの並列化も、基本的にはOpenMPと同じ戦法をとっており、さらに幅広いデバイス(Embedded GPU, GPGPU, CPU, Accelerator...)への適用を念頭にしたチューニングがなされています。
NDT Scan Matcher外観
それではソースコードを読みこんでいきますが、前編では省略した、NDT Scan Matcherの外観から読んでいきたいと思います。
NDT Scan Matcherは、LiDARからの点群を受けとった時点から処理がはじまります。NDT Scan Matcherに限ったことではありませんが、Autowareのソースコードリーディングにおいては、まずそのnodeが購読するtopicを知り、そのtopicを処理するcallbackを見つける所が最初の一歩です。
LiDAR点に対しては、void NDTScanMatcher::callbackSensorPoints がまさにそのcallbackにあたります。
さて、いきなり色々な処理があり面くらう所ですが、NDTにおいてその処理の大部分を占めるのは、俗に “align” 処理と呼ばれるものであり、一例として経過時間を以下に添付しますが、実際の所、計算機パフォーマンス的にはalign処理さえ抑えれば良いということがわかります。
1align_time: 21.448ms (align処理が占めた時間、大体exe_time - 2.0ms程度)
2exe_time: 23.242ms (callbackSensorPoints全体の時間)
そして、そのalign処理を呼び出しているのが ndt_scan_matcher_core.cpp L.371 の箇所です。
上記で登場する ndt_ptr_ という変数は、NDT Scan Matcherの各実装を示しており、node起動時のパラメーターによってどの実装が使用されるか決まります。今回のOpenCL実装は、NormalDistributionTransformOCLクラスによって実装がなされている…かと思いきや、その実装はさらに、別の ndt_ptr_ (class名としてはndt_ocl::NormalDistributionsTransform) のalign関数、実際には親クラス (pcl::Registration) のalign関数を呼び出しており、この中で、その子クラスで実装される関数である、ndt_ocl::NormalDistributionsTransform::computeTransformationを呼び出しています。ここまでの相関関係を図示しておくと以下の通りになりますが、これは実装の形式の話であり、最終的に重要なものは、自己位置計算の実装である、computeTransformationです。

このcomputeTransformation関数の中では、マッチングスコアがよくなる方向へ移動、スコア計算の流れを何度かイテレーションし、スコア(正確にはスコアを元に計算した値)が事前設定した数値条件 (transformation_epsilon_) を満足したら、その時点での変換行列を最終的な結果として終了します。このようにalign処理は、移動とスコア計算のイテレーションという一連の流れのことであるとソースコードからわかります。
これ以降の処理追跡では、重要な部分を動的な観測から"あたり"をつけつつ、行っていきます。
さらに深くへ
ソースコード上では様々な処理が存在しますが、複雑な記述だからといって重要度が高い、あるいは処理負荷が高いといったのはよくある誤謬です。
今回はperfの結果可視化ツールのFlameGraphと、ValgrindのツールであるCallgrindの2つの結果を、ソースコードリーディングの座右に置きたいと思います。


Call Graphにおいて上から3番目の緑のBOXが callbackSensorPoints であり、先程のコードリーディングで登場しました。ここを起点に下に目を移していきます。最初の枝分かれで、 init の方は 72:1 で呼び出しの頻度が低いため、左に降りていきましょう。すると computeDerivatives があり、これがFlameGraphにも登場している、処理割合が大きい関数です。
最終的に2つの関数にたどりつきます。それは updateDerivatives と radiusSearch でありますが、後者は前編で解説をした部分ですので、ここで updateDerivatives をもう少し掘り下げて見てみましょう。

computeDerivatives は updateDerivatives および computePointDerivatives から成ることがわかります。
以上をまとめると、NDT align処理の主関数は下記のたった3つであり、これにより重点的に見ていく場所が明らかになりました。
- radiusSearch
- updateDerivatives
- computePointDerivatives
computeDerivativesの中では、まずSource各点に対するTarget内の近傍探索、点の雰囲気とのマッチングスコア計算、そしてスコアがよくなる方向を上記の関数を用いて計算しています。
ここからはOpenCL実装の話ですが、上記の通り"Source各点に対する並列化"が容易であるため、1, 2, 3をSource各点に対して呼び出すカーネル関数 computeDerivatives を用意しています。
なお、Autowareが採用している OpenMP版 でも同様の並列化が、omp_parallelを用いて実装されています。
(補足) 地図のVoxel分割と地図KD木構築実装
OpenCL版で大きく異なるのは、むしろ地図のVoxel分割(およびそのKD木の構築)の部分であり、概念としては前編の通りですが、今一度package化に際しての実装を説明しておきます。
OpenCL版NDT Scan Matcherではndt_ocl::NormalDistributionsTransform::setInputTarget関数内のinitから、target_cells_.filter()関数(なお、target_cells_の型は、ndt_ocl::VoxelGridCovariance<PointTarget>) 、さらにPCLの関数を経由した後、最終的に voxel_grid_covariance_ocl_impl のこの箇所で木を構築しています。
OpenMPとの違いとしては、FLANN Libraryを経由せず、そのメモリ配置を voxel_grid_covariance_ocl_impl 内で任意に制御できる点にあります。この点は組み込み環境の制限されたメモリ環境においては必須となります。
そして最終的に作成された木メモリは、SVM (Shared Virtual Memory) argumentとしてkernelに渡され、デバイス側の近傍探索に使用されます。
スコア計算部の"命令実行的性質"
計算量といってしまうと、それはランダウ表記で示される、入力数に対するチューリングマシン上での操作手数の関係(スケーラビリティ)という抽象性を持つものになってしまいますが、ここではより具体的に、特定の命令セット命令を持つ(load/store型)計算機上における、命令の実行性質をみたいと思います。
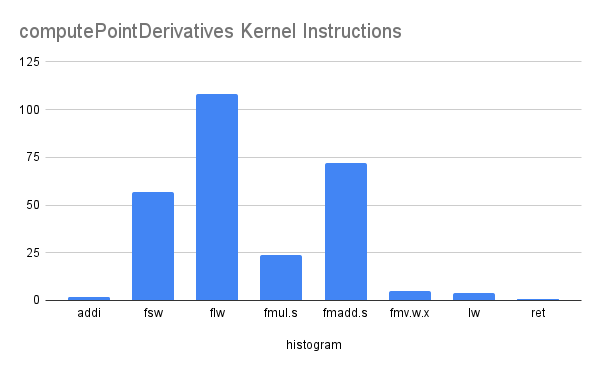
computePointDerivatives
2つの行列演算といくつかの行列のエレメント生成から成ります。
- j_ang * x4 (<8, 4> * <4, 1>)
- h_ang * x4 (<16, 4> * <4, 1>)
いずれもかなり小規模な行列であるため、行列演算自体のカーネル化やSIMD packedな演算化は行っていません。実際にカーネルコードを、RISC-Vのコンパイラ(RV32if)でコンパイルした結果における、命令ヒストグラムを見てみます。
大体がflw(FPRメモリロード) → fmadd.s(乗算加算複合) → fsw(FPRメモリストア)の系統であり、またspill outも極端でないため、fsw << flwとなっていることがわかります。ちなみにfmv.w.xはGPR → FPR移動命令だったり、retは(仮想命令)関数リターン(jalr x0)だったりしますが、本筋とは関係ありません。ちなみに乗算加算複合命令はgccでは-O3でないと出現しないようです。
updateDerivatives
多数の小規模行列演算と、スカラー値演算、およびexponent演算が使用されているのが特徴的です(スカラー値演算も多数ありますが、以下では割愛しています)。
-
e_x_cov_x<scalar> = exp(-gauss_d2<scalar> * x_trans4<1, 4>.dot(x_trans4<1, 4> * c_inv4<4, 4>) * 0.5f
-
c_inv4_x_point_gradient4<4, 6> = c_inv4<4, 4> * point_gradient4<4, 6>
-
x_trans4_dot_c_inv4_x_point_gradient4<6, 1> = x_trans4<1, 4> * c_inv4_x_point_gradient4<4, 6>
-
x_trans4_x_c_inv4<1, 4> = x_trans4<1, 4> * c_inv4<4, 4>
- point_gradient4_colj_dot_c_inv4_x_point_gradient4_col_i<6, 6> = point_gradient4.transpose()<6, 4> * c_inv4_x_point_gradient4<4, 6>
-
for i in 0 ... 5
- x_trans4_dot_c_inv4_x_ext_point_hessian_4ij.noalias()<6, 1> = x_trans4_x_c_inv4<1, 4> * point_hessian_.block<4, 6>(i * 4, 0)
最終的に、このupdateDerivativesの返却値がscoreとなり、これをinput点群数で割り正規化したものが、Transform Probabilityとして、推定のもっともらしさを表す数値として使用されることになります。
こちらも、RISC-Vコンパイラでのコンパイル結果とその命令分布を見てみましょう。

こちらはソースコードでも依存関係のある行列演算であるため、flwやfswよりもかなりfmul.s, fmadd.sの比重が大きいこととちょうど符合しています。
OpenCL実装について
紹介したOpenCL実装とOpenMP実装について、実際に(README記載の)サンプルを動作させて比較してみます。今回は、OpenCLもCPUにoffloadする形となっています。
Align TimeとTransform Probabilityの時間推移


結論としては、平均的にOpenCLの方がAlign Timeの時間は大きく、分散が小さいです。これは、OpenMPでは処理のロードバランシング等の最適化が行われており、応答性に関してはより優れた結果になっていると思われます。例えば、GPGPUやAccelerator等のCPU外のdeviceにもoffloadすることが可能な点がOpenCL版の魅力ではありますが、ナイーブな実装もあってCPUは少し苦手といった所のようです。
Transform Probabilityとしては同程度の推移です。
最後にFlameGraphを取得してみると、libgomp (OpenMP) libraryの代わりに、intel::internal::arena (Threading Building Block)が使用されていることがわかります。

ndt_ocl packageのREADMEでは、Intel環境におけるOpenCL 2.x環境の構築の例も紹介していますので、実行する際にぜひご参照ください。
リソース管理厳格化
OpenCLの実装にあたっては、使用する各種のリソースにも制限を意図的に加えています(いずれも設定が可能です)。
実際問題として車載環境のような組み込みによった環境では、動的で潤沢なメモリ確保ができない場合の方が多いですし、何より実行毎に予想できない挙動であることは、一つのリスクとなります。
重要なことは、平均でも最小でもなく、最大値を予め設定できるということです。
具体的には、NDT Scan Matchingにおいて、その処理量に影響を与える要素は3つしかなく、以下の3要素の最大値を予め定めさえすれば、処理時間を予測できるということになります。
- LiDAR点数
- 発見近傍Voxel数
- スコア値計算の最大繰り返し数
OpenMP実装では、3のmax_iterationのみの制限でありますが、OpenCL実装では全てに以下のような制限をかけることができます。
- LIMIT_NUM (MAX_NEIGHBOR_VOXELS)
- Radius Searchが発見する近傍Voxcelの限界数、これを超過すると単純に近傍として追加されず、Scan Matchingが不安定となる恐れがあります。
- MAX_PCL_INPUT_NUM (MAX_NUM_OF_LIDAR_POINTS)
- LiDARからの入力点群数の最大値を設定する。
おわりに
前編/後編と2回にわたり、NDT Scan Matchingの計算面の調査を行い、その結果を一緒に眺めてきましたが、いかがでしたでしょうか。
途中から解析や、再実装の話に始終してしまいましたが、腰をすえてソースコードを追ってみる時、ただやみくもに読むよりも定量的に姿を捉えながら全体を理解していく、そんな一例をご紹介できたかと思います。
魔法のような自動運転のアルゴリズムも、実装となってしまえばただの計算です。Autowareはオープンなソフトウェアです。実際に読み、触れ、動作させることで理解ができます。臆することなく挑戦していきましょう!