こんにちは、ティアフォーでVisual SLAMの研究をしている石田です。今回は、自動運転における自己位置推定に関してVisual SLAMの重要性と課題についてお話ししたいと思います。
Visual SLAMの要素技術であるVisual Odometryの例
Reference: Alismail et al., 2016
Dataset: Computer Vision Group - Dataset Download
自動運転における自己位置推定
車両が地図上のどこを走っているかを推定する技術(自己位置推定)は自動運転において欠かせない要素のひとつです。自分がどこを走っているかを把握できなければ迷子になってしまいますし、自分が走っている場所の先に何があるかを把握することも難しくなってしまいます。
現状のAutowareではレーザー光を用いたLiDARという巨大なセンサーを車両に搭載して自己位置推定を行っています。あらかじめ作っておいた地図の構造と、LiDARで得られた車両周囲の3次元構造を照らし合わせて自分がどこにいるのかを把握するというわけです。ジグソーパズルをはめ込むようにして位置推定をしていると考えるとイメージが湧きやすいかもしれません。
しかしながらLiDARベースの位置推定手法には大きく2つの欠点があります。
ひとつはLiDARそのものが非常に高価であることです。性能のいいものでは数千万円もするものがあります。これを世の中のクルマひとつひとつに取り付けて走らせることは現実的ではないため、なんらかの方法でコストを下げる必要があります。
もうひとつは構造特徴に乏しい場所では性能を発揮できないことです。絵柄のないジグソーパズルをイメージしてみてください。ピースひとつひとつが異なる形をしていたら、それぞれのピースは特定の場所にはまります。しかし、もし全てのピースが正方形だったら... これはもはやジグソーパズルの意味を成しませんよね。全てのピースがどこにでもはまってしまいます。同じように、構造的な特徴に乏しい場所(平原やトンネルなど)では、LiDARはどこにでも”はまって”しまうため、位置を一意に定めることができません。
これらの問題を解決するために現在私が取り組んでいるのがVisual SLAMという技術です。
Visual SLAMとは、視覚情報を用いて地図を作成し、同時に地図内での自己位置を推定する技術です。 また、あらかじめ作成しておいた地図に対して、その地図内でどこにいるのかを推定する relocalization という技術も活発に研究されています。
Visual SLAMの最大の利点は設備の安さです。Visual SLAMは基本的にカメラやIMU(物体の加速度や回転速度を測るセンサー)からの入力に基づいて動作します。これらのセンサーは安価に手に入るため、数万円で位置推定を始めることができます。また、Visual SLAMは視覚情報をもとに動作するため、構造特徴に乏しい場所であっても車の位置を推定することができます。さらに、カメラやIMUだけでなく、LiDARなどの他のセンサーと組み合わせることによってロバスト性を向上させ、さまざまな場所を走ることができるようになります。
自動運転ではあらかじめ作成しておいた地図との照合による位置推定が基本となるため、通常走行の範囲では relocalization が主体となります。しかし、LiDARがうまく動かない場所ではLiDARで地図を作ることが難しいため、Visual SLAMによって車両の位置推定をしつつLiDARによって地図を作ることも想定されています。
Visual SLAMの技術的チャレンジ
自動運転におけるVisual SLAMの最大の課題は、なんといってもそのロバスト性です。自動車はあらゆる環境のあらゆる場所を走ります。街中、ハイウェイ、峠、住宅街、晴れ、雨、雪、夜…
現在はODD(運行設計領域)対象外の環境もあるとはいえ、トンネルや逆光など、日常生活でよく目にするシーンの中にもVisual SLAMにとっては難しいものがあります。こういった場所で安定して動作する手法を設計し実装するのは至難の業ですが、技術者の腕の見せどころでもあります。
Visual SLAMにとって難しい環境は大きく分けて2つあります。ひとつは暗い場所、もうひとつは動く物体が多い場所です。
Visual SLAMは画像の情報から地図の3次元構造を計算し、その地図に対して自分がどの程度動いたかを推定することによって位置を把握します。画像からどのような情報を抽出するのかは手法によって大きく異なりますが、画像の特徴がよく現れている点(特徴点)を用いるものが一般的です。カメラから得られた画像1枚1枚から特徴点を抽出し、それらの幾何関係を利用して3次元地図を作ったり、位置推定を行ったりします。しかし、暗い場所ではそもそも画像から得られる情報が大きく減ってしまいますし、画像から有用な特徴点を抽出することも難しくなります。露光時間が長くなってブレが大きくなってしまいますし、カメラの感度が高くなって明るいものは極端に明るく映ってしまうためです。暗い場所でVisual SLAMを安定して動作させるためにはカメラ本体も含めた包括的な設計が必要になるため、これは非常にチャレンジングな問題だと言えます。
動く物体の扱いも大きな課題です。既存のVisual SLAMのほとんどは周囲の環境が動かないことを仮定しており、動く物体の扱いをあまり考慮できていません。このため、周囲に移動物体がたくさんあると、自分が動いているのか、それとも環境が動いているのかを判別できなくなってしまいます。自動車は周囲に動く物体がたくさんある場所をよく走るため、Visual SLAM単体で位置推定を行うことはせず、他のセンサーと組み合わせることが必須となります。
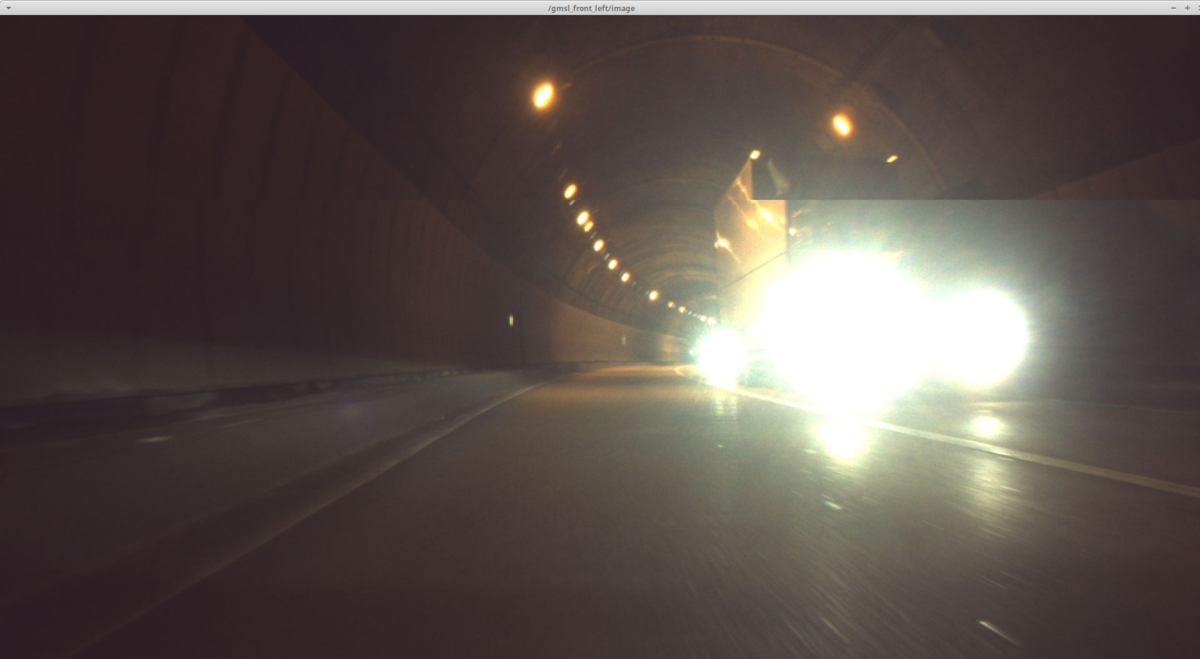
トンネル内で得られた画像の例
カメラの感度が上がっている一方で対向車のライトは非常に明るいため
カメラが扱える明るさを大きく超えてしまっている
自動運転車にとって最も難しい環境のひとつがトンネルです。トンネル内部にはGNSS(GPSなどの衛星測位システム)の信号が届きませんし、構造的な特徴に乏しいためLiDARの信頼性も低くなります。また、トンネルはVisual SLAMにとってもやはり課題のひとつです。
トンネルの内部は暗いため有用な視覚情報を得ることが難しいですし、全体が暗いのに対して周囲の車のライトは明るいため、ひとつの環境の中で非常に激しい光量変化が起きてしまいます。また、トンネル出入口では視野全体の明るさが一気に変わるため、やはり極端な光量変化に対応できる機材およびアルゴリズムが求められます。それに加えて、周囲の全ての車が移動物体なので、これらもうまく扱わなければなりません。
こういった難しい環境でも安心して走れるよう、我々はハードウェアからソフトウェア、さらにはインフラまでも対象として、日々研究開発を行っています。
Visual SLAMの面白さ
Visual SLAMはコンピュータビジョンの総合格闘技です。画像処理に対する基礎的な知識はもちろんとして、エピポーラ幾何や数理最適化に対する深い理解が要求されますし、IMUなど他のセンサと組み合わせる場合はカルマンフィルタや制御理論の知識も必要になります。また、Visual SLAMはやや大規模なシステムになることが多いため、コードをきれいに管理したり、綿密にテストしたりする能力も求められます。特に自動運転では非常に高い安全性が求められるため、他のVisual SLAMのアプリケーションと比べると徹底したテストが必要となります。
自動運転では、Visual SLAMは省電力デバイス上で高速に動作することが要求されるため、コンピュータの能力をフルに発揮するための実装力も必要になります。車に数千ワットの巨大なコンピュータを載せるわけにはいきませんし、かといってゆっくり動作すると車の運行性能や安全性が犠牲になってしまいます。先ほども述べたように、Visual SLAMの多くは画像から特徴点を抽出し、それらの幾何関係を利用して地図作成と位置推定を行います。カメラは1秒間に何十枚もの画像を出力しますし、1画像から得られる特徴点の数は数百から数千にもなります。自動運転では、省電力デバイスの上で、大量の特徴点から信頼できるものを選び出し、地図作成と位置推定をできるだけ高速に行う必要があるというわけです。また、地図を作っていくと誤差が蓄積してどんどん歪んでいってしまうため、この歪みを補正する処理も必要になります。小さなコンピュータで大量の情報を正確かつ高速に処理することがVisual SLAMの最大のチャレンジであり、これを徹底した安全管理と品質管理に基づいて自動車に載せていくことが私にとっての自動運転の面白さです。
Visual SLAMを自動運転に活用するためには、情報工学の理論から実装までありとあらゆる知識が必要とされます。自分がいままで学んできたことを全てつぎ込んでものをつくることが、この仕事の最大の面白さです。
もしあなたが自動運転車に乗る日が来たら、車のまわりを細かくチェックしてみてください。もしかしたらカメラがたくさんついていて、そのうしろでは私が作ったシステムが動いているかもしれません。
ティアフォーでは、自己位置推定に関するリサーチャーとエンジニアを絶賛募集しています!もしご興味ある方がいましたら、以下のURLからご応募ください!!