こんにちは、ティアフォーでパートタイムエンジニアをしている佐々木です。
今回はLinuxに搭載されているスケジューラの一つ、SCHED_DEADLINEについて紹介していきたいと思います。自動運転には多数のクリティカルタスクがあり、自動運転の安心・安全をしっかりと確保するためにはこのスケジューラを上手に設定することでこれらのクリティカルタスクが効率的にまた互いにコンフリクトすることなくリアルタイムに処理されることを担保する必要があります。なお、この記事で紹介するコードはLinuxカーネル5.4.0 (Ubuntu 20.04 LTSのベースカーネル) を元としています。
また、ティアフォーでは「自動運転の民主化」をともに実現していく、学生パートタイムエンジニアを常時募集しています。自動運転を実現するためには、Softwareに関してはOSからMiddlewareそしてApplicationに至るまで、Hardwareに関してはSensorからECUそして車両に至るまで異なるスキルを持つ様々な人々が不可欠です。もしご興味があれば以下のページからコンタクトいただければと思います。
tier4.jp
Linuxのスケジューラについて
まず、スケジューラとはなんぞや?という話から始めると、CPU上で実行するタスク(Linuxではスレッドがスケジュール単位)が複数あるとき、どのタスクから実行するかを決めるものです。
スケジュールの仕方のことをスケジューリングポリシーと呼び、Linuxには現在6つのスケジューリングポリシーが搭載されています。
搭載されているポリシーはkernel/sched/sched.hで確認することができます。
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
SCHED_NORMAL (SCHED_OTHER)は通常のタスクに使われるスケジューラで、現在LinuxだとCompletely Fair Scheduler (CFS)という赤黒木を使用するできるだけ平等にタスクに実行時間を割り当てるスケジューラです。
SCHED_FIFOとSCHED_RRは静的優先度を使うスケジューリングポリシーです。
優先度が高いタスクが低いタスクより優先的にスケジュールされ、高優先度のタスクでコアが占有されている時、低優先度のタスクは実行されません。
逆に、低優先度のタスクが実行開始後に高優先度のタスクが来たら低優先度のタスクは直ちに中断し、高優先度のタスクが実行開始します。
SCHED_FIFOとSCHED_RRは0~99の優先度を持ち、双方この優先度に従ってスケジューリングを行いますが、挙動の違いは同じ優先度を持つタスクが複数存在する時、SCHED_FIFOはFirst-In-First-Out (FIFO)キューを用いて逐次実行し、SCHED_RRはRound-Robin (RR)を用いて設定したtime slice事に実行タスクを切り替えます。
SCHED_NORMALのタスクは優先度が100以上なので、SCHED_FIFOとSCHED_RRは任意のSCHED_NORMALタスクより優先され、SCHED_NORMALのタスクと比較してSCHED_FIFO/SCHED_RR/SCHED_DEADLINEのタスクをリアルタイムタスクと呼んだりします。
また、SCHED_FIFO/SCHED_RRはPOSIX.1-2001で規程されているので、pthread_setschedparam(3)を使って設定することが可能です。
SCHED_BATCH, SCHED_IDLEについては本記事では省略します。
Earliest Deadline First (EDF)
さて、本題のSCHED_DEADLINEについて説明していきます。
SCHED_DEADLINEはLinux 3.14以降に標準搭載されたEarliest Deadline First (EDF)というスケジューリングポリシーをベースとしたスケジューラで、設定されたデッドラインが一番近いものから実行していきます。
EDFの例を見てみましょう。
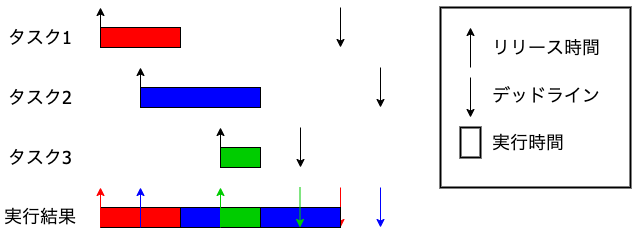
- まずt=0にタスク1がリリースされ、他のタスクはないのでそのままスケジュールされます。
- 次にt=1にタスク2がリリースされますが、デッドラインがタスク1のデッドラインより後ろなのでタスク1が終わるまで待機キューに入れられます。
- t=2になりタスク1が実行終了するので、タスク2が実行を開始します。
- t=3ではタスク3がリリースされ、今度はタスク3のデッドラインの方が近いので、タスク2は中断(プリエンプション)されます。
- t=4でタスク3が終了するので、中断されていたタスク2が実行を再開します。
よって実行結果は図の最下部のようになります。
例はシングルコアでのスケジューリング例ですが、マルチコアでも同様のスケジューリングポリシーが使えます。
SCHED_DEADLINEの使用方法
ここではSCHED_DEADLINEの使い方を簡単に説明していきます。
基本は公式ドキュメントDeadline Task Schedulingを参照してください。
SCHED_DEADLINEポリシーはPOSIX規格ではないのでpthread_setschedparam(3)ではなくsched_setattr(2)を使います。(sched_setscheduler(2)とsched_setparam(2)の組み合わせでも同様の設定ができます)
sched_setattr(2)の引数を説明していきます。
int sched_setattr(pid_t pid, const struct sched_attr *attr, unsigned int flags);
pid:ポリシーを設定する対象のpid/0の時は呼び出しスレッドが設定対象になる。attr:スケジューリング属性(attribute)後述flags:現状では何も意味がないので0を設定(ドキュメントには将来の機能拡張のために確保となっている)
さてスケジューリング属性attrの構造体であるstruct sched_attrは以下のようになっています。
struct sched_attr {
__u32 size;
__u32 sched_policy;
__u64 sched_flags;
__s32 sched_nice;
__u32 sched_priority;
__u64 sched_runtime;
__u64 sched_deadline;
__u64 sched_period;
};
コメントにも書かれている通りsched_niceとsched_priorityはSCHED_DEADLINEでは使いません。
sched_priorityは0を設定するものの、内部ではSCHED_DEADLINEタスクは優先度が-1に設定されており、任意のSCHED_FIFO,SCHED_RRタスクよりも優先されます。
SCHED_DEADLINEでは実行時間sched_runtime、デッドラインsched_deadline、周期sched_periodを使います。
実際にSCHED_DEADLINEを使って実行時間10ms/デッドライン30ms/周期40msのタスクの設定してみると以下のようになります。
sched_attr attr;
attr.size = sizeof(attr);
attr.sched_flags = 0;
attr.sched_nice = 0;
attr.sched_priority = 0;
attr.sched_policy = SCHED_DEADLINE;
attr.sched_runtime = 10 * 1000 * 1000;
attr.sched_deadline = 30 * 1000 * 1000;
attr.sched_period = 40 * 1000 * 1000;
unsigned int flags = 0;
sched_setattr(0, &attr, flags);
なお、sched_periodは必須ではなく、設定しない場合sched_deadlineが周期として使われます。
SCHED_DEADLINEを使用する際の注意点
SCHED_DEADLINEを使うにはsched.hをインクルードして前セクションの通りに設定すれば基本的に動きます。(環境によってはlinux/sched.h)
が、環境によっていくつかハマりポイントがあるので、いくつか紹介していきます。
sched.hがない/インクルードしてもsched_setattrが見つからない
環境によってsched.hが見つからない/インクルードしてもsched_setattrがコンパイルされない場合があります。(Ubuntu 18.04 LTS等)
自分の環境では以下のようにシステムコールを直打ち/構造体を直接宣言することで使用できました。
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <linux/unistd.h>
#include <linux/kernel.h>
#include <linux/types.h>
#include <sys/syscall.h>
#include <pthread.h>
#define SCHED_FLAG_DL_OVERRUN 0x04
#define gettid() syscall(__NR_gettid)
#define SCHED_DEADLINE 6
#ifdef __x86_64__
#define __NR_sched_setattr 314
#endif
#ifdef __i386__
#define __NR_sched_setattr 351
#endif
#ifdef __arm__
#define __NR_sched_setattr 380
#endif
#ifdef __aarch64__
#define __NR_sched_setattr 274
#endif
struct sched_attr {
__u32 size;
__u32 sched_policy;
__u64 sched_flags;
/* SCHED_NORMAL, SCHED_BATCH */
__s32 sched_nice;
/* SCHED_FIFO, SCHED_RR */
__u32 sched_priority;
/* SCHED_DEADLINE (nsec) */
__u64 sched_runtime;
__u64 sched_deadline;
__u64 sched_period;
};
int sched_setattr(pid_t pid, const struct sched_attr *attr, unsigned int flags){
return syscall(__NR_sched_setattr, pid, attr, flags);
}
SCHED_DEADLINEが設定されない
sched_setattrを使っているのにSCHED_DEADLINEポリシーが適用されていないという場合はsched_setattrの返り値をみてみます。
正しく設定されている場合は0、失敗した場合は-1を返します。
sched_setattrにはいくつかのerrnoが設定されてますがSCHED_DEADLINEを使う場合、以下の3つがよく遭遇します。
EPERM:root権限で実行していない。SCHED_DEADLINEはユーザー権限では動きません。EINVAL:パラメータが正しく設定されてない、または周期等の値が210~263の間にない時にこのエラーがでます。EBUSY:sched_setattrでSCHED_DEADLINEを設定する際、使用率=実行時間/周期の計算が行われます。この使用率をスケジューラが受け入れるだけの余裕があるかを計算し、無理な場合EBUSYを返します。これにより最低限のデッドライン保証をチェックしています。
特に複数のタスクをSCHED_DEADLINEポリシーで動かす場合EBUSYエラーが起こり易いので、可能ならデッドラインを長めに見積もると良いでしょう。
詳しくここのvalidationを知りたい方はここに実装があります。
まだRC版である最新の5.11系ではこのvalidationが高速化されるみたいです(参照)。
tasksetでCPU制限した場合に失敗する
SCHED_DEADLINEとtasksetを併用するとエラーを起こすケースがあります。
これはSCHED_DEADLINEのCPUハンドリングがtasksetによるマスキングに対応していないためと思われます。
実行するコアを限定したい場合はcgroupのcpusetで設定することで上手く動きます。
Constant Bandwidth Server (CBS) について
さて、SCHED_DEADLINEはEDFポリシーに従ってスケジューリングしてくれますが、適切なdeadlineとruntimeを設定するのはユーザーの責任となっています。
設定が適切でなければ、仮にプロセスが無限loopなどで実行し続けてdeadlineを超過したとしても、何も起こらずCPUリソースが占有され続けることになります。
これを防ぐためにLinux4.16以降ではConstant Bandwidth Server (CBS)という機能がついています。
CBSは実行時間を制限するもので、SCHED_DEADLINEでは設定されたスレッドの実行時間がsched_runtimeを超えた場合、シグナルを送るように設定することができます。
attr.sched_flags=SCHED_FLAG_DL_OVERRUNと設定することで超過時にSIGXCPUというシグナルをスレッドに送ります。
このシグナルをハンドリングすることで超過対策を行うことができます。
またCBSにはreplenishというもう一つの機能があります。
例えばタスクAの実行中にデッドラインが近いタスクBがリリースされたことによりAは中断(プリエンプション)され、Bが終了しAを再開しようとしたときにAのデッドラインを過ぎていて本来ならばAを実行できないといったケースがあります。
このような中断はユーザが関知することができない以上、Linuxの実装ではタスク自体は実行時間が設定されたruntimeを超えない限り、デッドラインを超過していても最後まで実行させるというポリシーを取っています。
この最後まで実行させるために追加の実行時間を確保する仕組みがreplenishになります。
内容としては残りの実行時間(runtime-中断するまでに実行した時間)をruntimeとし1周期後のデッドラインをデッドラインと変更し、再度スケジューリングされます。
このCBSがあるため厳密なEDF通りの実行にならないことを考慮した上でSCHED_DEADLINEを使う必要があります。
SCHED_DEADLINEの実装
最後にSCHED_DEADLINEの実装を簡単にみてみましょう。
実装は主にkernel/sched/deadline.cに記述されています。
まず、SCHED_DEADLINEのランキューをみてみます。
struct dl_rq {
struct rb_root_cached root;
unsigned long dl_nr_running;
struct dl_bw dl_bw;
u64 running_bw;
u64 this_bw;
u64 extra_bw;
u64 bw_ratio;
};
root:ランキューを管理する構造体dl_nr_running:デッドラインクラスのスレッドで実行可能な数*_bw:このbwはbandwidthの略で使用率とほぼ同義で、先ほどのスケジューリング可能性のチェック等で使われます。
次にデッドラインクラスをみてみます。
デッドラインクラスはRTクラス(SCHED_FIFO/SCHED_RR)より上、最上位クラスのSTOPクラスより下になっています。
const struct sched_class dl_sched_class = {
.next = &rt_sched_class,
.enqueue_task = enqueue_task_dl,
.dequeue_task = dequeue_task_dl,
.yield_task = yield_task_dl,
.check_preempt_curr = check_preempt_curr_dl,
.pick_next_task = pick_next_task_dl,
.put_prev_task = put_prev_task_dl,
.set_next_task = set_next_task_dl,
.task_tick = task_tick_dl,
.task_fork = task_fork_dl,
.prio_changed = prio_changed_dl,
.switched_from = switched_from_dl,
.switched_to = switched_to_dl,
.update_curr = update_curr_dl,
};
ここで重要なメンバを3つほどみていきます。
enqueue_task:タスク追加時の処理dequeue_task:タスク削除時の処理pick_next_task:次に実行するタスクの選択処理
タスク追加時の処理
static void
enqueue_dl_entity(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se, int flags)
{
BUG_ON(on_dl_rq(dl_se));
//省略
__enqueue_dl_entity(dl_se);
}
static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags)
{
struct task_struct *pi_task = rt_mutex_get_top_task(p);
struct sched_dl_entity *pi_se = &p->dl;
//省略
enqueue_dl_entity(&p->dl, pi_se, flags);
if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
enqueue_pushable_dl_task(rq, p);
}
DEADLINEタスク追加時の処理は、優先度継承、CBSに関連する例外処理等がありますが、重要な追加時の関数は__enqueue_dl_entityであることがわかります。
static void __enqueue_dl_entity(struct sched_dl_entity *dl_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
struct rb_node **link = &dl_rq->root.rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_dl_entity *entry;
int leftmost = 1;
BUG_ON(!RB_EMPTY_NODE(&dl_se->rb_node));
while (*link) {
parent = *link;
entry = rb_entry(parent, struct sched_dl_entity, rb_node);
if (dl_time_before(dl_se->deadline, entry->deadline))
link = &parent->rb_left;
else {
link = &parent->rb_right;
leftmost = 0;
}
}
rb_link_node(&dl_se->rb_node, parent, link);
rb_insert_color_cached(&dl_se->rb_node, &dl_rq->root, leftmost);
inc_dl_tasks(dl_se, dl_rq);
}
この実装からデッドラインクラスのランキューには通常タスクのCFSでも使われている赤黒木が使われていて、タスク構造体をデッドラインを基準に挿入していることがわかります。
赤黒木は安定した二分木なので、これによりデッドラインが一番近い(最小値)のタスクを選択しスケジュールすることが可能になっています。
タスク削除時の処理
削除に関する実装も同様に__dequeue_dl_entityを見ると赤黒木から終了したタスクの削除を行っていることがわかります。
static void __dequeue_dl_entity(struct sched_dl_entity *dl_se)
{
struct dl_rq *dl_rq = dl_rq_of_se(dl_se);
if (RB_EMPTY_NODE(&dl_se->rb_node))
return;
rb_erase_cached(&dl_se->rb_node, &dl_rq->root);
RB_CLEAR_NODE(&dl_se->rb_node);
dec_dl_tasks(dl_se, dl_rq);
}
次に実行するタスクの選択処理
最後に次に実行するタスクの選択処理をみてみましょう。
static void set_next_task_dl(struct rq *rq, struct task_struct *p)
{
p->se.exec_start = rq_clock_task(rq);
dequeue_pushable_dl_task(rq, p);
if (hrtick_enabled(rq))
start_hrtick_dl(rq, p);
if (rq->curr->sched_class != &dl_sched_class)
update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 0);
deadline_queue_push_tasks(rq);
}
static struct sched_dl_entity *pick_next_dl_entity(struct rq *rq,
struct dl_rq *dl_rq)
{
struct rb_node *left = rb_first_cached(&dl_rq->root);
if (!left)
return NULL;
return rb_entry(left, struct sched_dl_entity, rb_node);
}
static struct task_struct *
pick_next_task_dl(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct sched_dl_entity *dl_se;
struct dl_rq *dl_rq = &rq->dl;
struct task_struct *p;
WARN_ON_ONCE(prev || rf);
if (!sched_dl_runnable(rq))
return NULL;
dl_se = pick_next_dl_entity(rq, dl_rq);
BUG_ON(!dl_se);
p = dl_task_of(dl_se);
set_next_task_dl(rq, p);
return p;
}
実装によると選択処理は5ステップから構成されています。
sched_dl_runnableでランキューを確認し、タスクが実行する可能か確認pick_next_dl_entityで赤黒木からデッドラインが一番近いものを選択dl_task_ofで選択したスケジュールから実行するタスク構造体ポインタを抽出set_next_task_dlで実行開始時間を記録- 次に実行するタスク構造体ポインタを返す
CBSの処理が絡むとややこしいですが、それ以外の基本的な処理は赤黒木を使ったわかりやすい実装になっていることがわかります。
まとめ
今回はLinuxに搭載されているEDFスケジューラのSCHED_DEADLINEを簡単にみてみました。
なお今回は簡単にまとめる関係上Symmetric Multi-Processing(SMP)の処理部分は省いています。
リアルタイムに対応するためにRT_PREEMPT_PATCHを導入する手法も知られてはいますが、SCHED_DEADLINEを使う分には何も変更することなく値を設定するだけで簡単にEDFスケジューラがLinuxで使えるので、是非興味ある方はいじって見ると面白いと思います。
参照
www.kernel.org
linuxjm.osdn.jp
linuxjm.osdn.jp







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}