こんにちは、ティアフォーエンジニアの村上です。今回は、ROS 2の通信機能に関するお話をしたいと思います。
自動運転OSSの「Autoware」は、ROS 2の上に構築されており*1、ROS 2はその通信 (出版/購読) backendとしてDDS (Data Distribution Service) を採用しています。多くのプロセスからなるAutowareにおいて、通信は注目すべき要素です。安心・安全な自動運転の実現のためには、Autowareの機能自体はもちろんのこと、通信のようなbackendについて、各systemに対するtuningをすることは不可欠です。 今回はそのROS 2/DDSについて調査した時のreportです。
ROS 2のProtocol Stack
従来のROS (便宜上ROS 1と呼称します) においては、独自の出版/購読の仕組みを実装していましたが、ROS 2ではDDSのAPI等をinterfaceとして、具体的な出版/購読の実装をROS本体から分離しました。このlayerこそがrmw (ROS MiddleWare)です。我々は各DDS実装に対するrmwを使用することで、application側でコードを変更することなく、各DDS実装を切り替えて使用することができます。
下記の図は、ROS 2の、特に通信に着目したProtocol Stackです。

backendは様々なものを考えることが可能で、layerというものではありません。例えばPOSIXで提供されているある種のprocess間通信、RTPSのような通信protocol、RTOS (Realtime OS) でサポートされている特殊な通信API、直接Network-on-Chipなどのhardwareを扱うなんてことも考えられるでしょう。
このように、rmwやrclcによって、個別の実装は隠蔽されており、各backendに適したrmwを使いわけることで、tuningを行うことができます。
ここまでの用語を整理しておきましょう。
- RMW (ROS Middleware)
- 各DDS実装あるいは各backendの差を吸収、あるいは最適化を施している層。rclcに対して共通のinterfaceを提供する。
- DDS (Data Distribution Service)
- publish/subscribe programmingを実現するAPIを規定する。同じ立ち位置のAPIとしては、例えばSocketやMPIがある。
- RTPS (Real Time Publish-Subscribe)
- transport-layerよりも上層に位置する通信protocolの一つ。同じ立ち位置の仲間としてはHTTPなど。protocolの位置関係は、DDS API over [RTPS/UDP/IP/Ethernet]のようになる。
共有メモリを使用するrmw
Autowareの通信を考えるとき、いかにも最適化できそうなものとして、例えば以下のような特徴があります。
- 高性能sensor群からの大きなdataの通信が存在するが、出版者と購読者が1対1で、dataを出版後に参照することはない
- GPGPUを活用している認識以外の大部分の処理は、1 hostで処理されている計算機systemである
帯域量を求めるROS node間通信と応答時間を求めるROS node間通信は、Autowareにおいて混在していますが、今回は後者の応答時間を考えたいと思います。
応答時間に対するROS 1での最適化については、nodeletを積極的に使用していました。
nodeletは1 processの中で複数のnodeを実行する仕組みであり、その通信はpointer passing、所謂参照渡しとして実装できます。ROS 2においてもこの仕組みはexecutorという、より発展した形として提供されておりますが、これらが共通して抱えている課題点はapplication levelでの変更が必要な点です。nodeletを使用しない場合、ROS 1では、たとえ1 hostの計算機で閉じていようが、socket API over [TCP or UDP]経由の通信しかできません。
対してROS 2では、先に触れたrmwより下層の切り替えのみで最適化を行うことができ、applicationへの変更は一切必要ありません。
それでは実際に、今回の条件に適しているであろう、rmw_iceoryxを使用してみたいと思います。iceoryxはshared memory上でのdata転送を効率よく行う仕組みを提供しており、今回のようなlocalhost上限定の状況では、よい選択肢となります。このような転送はiceoryxの専売特許というわけではありませんので、実際にrmwの選定を行うときには、より広い選択肢があるでしょう。
(するどい方は、DDSのAPI等と濁したことに気がついているかもしれませんが、iceoryxはDDSのAPIを提供しているわけではありません。今回はrmwをI/Fとしますので、DDSに類する機能を内包さえしてしまえば、stackは厳密に積まれる必要はないのです。)
rmw_iceoryxの応答時間評価
rmw_iceoryxのbuild
環境は、Ubuntu 18.04 ROS 2 Eloquentです。rmw_iceoryxはgithubからcloseしてきてください。
基本的には、rwm_icoryxのreadmeのInstallationを参考にしますが、最後のcolcon buildにおいて、下記2点に注意してください。
- sys/acl.hがない場合;
apt install libacl1-dev - rosidl_runtime_cのcmake用のconfigがない場合; rmw_iceoryxがmaster(foxy用)かもしれません。eloquent用のbranchに切り替えてください。
cd src/rmw_iceoryx; git checkout -b eloquent origin/eloquent
サンプルプログラム
今回使用するpub/sub サンプルプログラムは、2MB/100msのtopicをpublish/subscribeさせ、その間のlatencyを出力するprogramです。この2MB/100msの数字は、高性能なsensor一つの出力を模しています。
実行
- まず、shared memory及びその上のpub/subを監督する処理を立ち上げます。
./iceoryx_ws/install/iceoryx_posh/bin/iox-roudi - 次に、以下のようにRMW_IMPLEMENTATIONを指定して、sample programを起動します。
source /opt/ros/eloquent/setup.bash source iceoryx_ws/install/setup.bash source pubsub/install/setup.bash RMW_IMPLEMENTATION=rmw_iceoryx_cpp ros2 launch comm inter_process_pubsub.launch.py
環境変数RMW_IMPLEMENTATIONを特に設定しなければ、default(fastrtps)による通信が行われます。また、latencyの出力については、launcherの設定で~/.ros/log/[日時]/launch.log以下に出すようにしています。
動作比較
応答速度としては、Fast RTPS > Ice Oryx > executorが予想されます。それぞれ応答速度と引き換えに制限が発生します。それは1 hostの制限であったり、単一障害点の発生であったり、published dataを参照するnode数 etc…であったりです。 また、使用したrmwはそれぞれdefaultの設定を使用しており、tuningの余地は十分にあります。
Fast RTPS (Default DDS)
上述の通り、何も設定しない状態でのpubl/subです。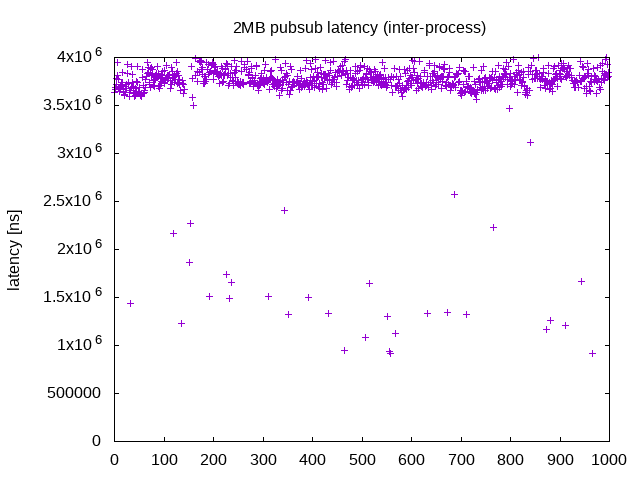
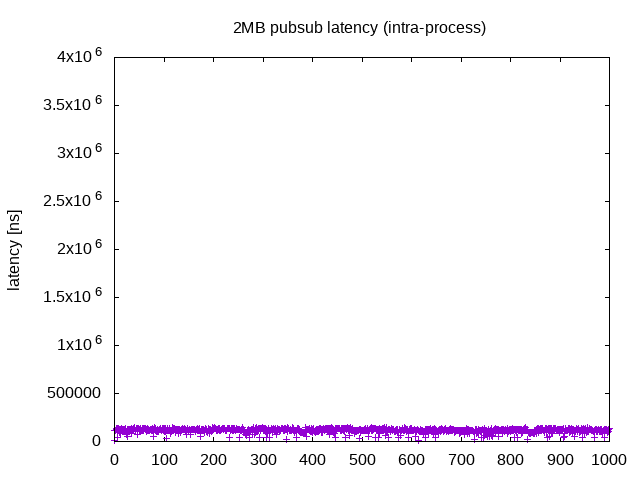
Process内 (executor)
rmw層下の話からは逸れる話ですが、先に触れたprocess内のpubsubでは、実装やコーディング制限が伴う可能性はあるものの、それに見あうだけの非常に高速な応答性があります。今回はsingle thread executorを使用しました。起動方法としてはros2 launch comm intra_process_pubsub.launch.pyで起動できます。
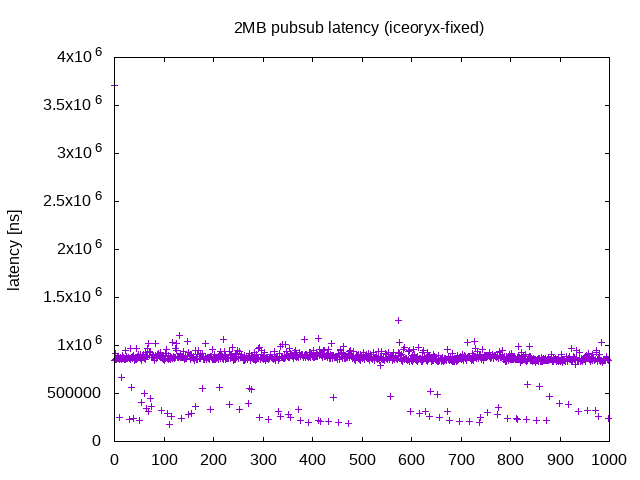
Ice Oryx (固定長message)
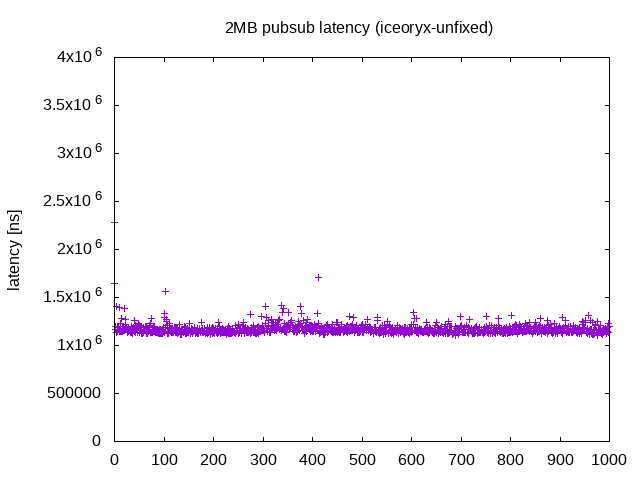
Ice Oryx (可変長messega)
上述のサンプルプログラムのvariable_messageブランチで計測ができます。固定長との違いは、message typeでstd_msgs/ByteMultiArrayを指定している点です。
最後に
今回は実験として、rmwを切り替えた時の応答速度の変化を見てみました。話を簡単にするため、Autowareではなくsample programの上で観測しましたが、Autowareにおいても十分期待ができる結果です。また、rmwの切り替えだけという、非常に簡単な方法でtuningができるということも実感できました。ただし、観測結果については通信以外の部分の考慮をしていないため、厳密な評価ではないでしょう。それでも、大雑把にこれだけの差が出ることは、大変に興味深い結果です。
ティアフォーでは、今回ご紹介したように、自動運転ソフトウェアの開発だけでなく、自動運転という最先端のApplicationに対するECU/Middlewareの設計開発も行っており、自動運転の安心・安全を確保し「自動運転の民主化」をともに実現してくため、様々なエンジニア・リサーチャーを募集しています。もしご興味があればカジュアル面談も可能ですので以下のページからコンタクトいただければ幸いです。
補遺、参照
- ROS on DDS (ROS本家tech. blog)
- ECU; 車載向けのcontroller(計算機)の意味。完全自動運転が要求するspecは、通常の車載system、自動運転支援systemと比べても幾分か高い。性能及び組み込み的な安全性を考慮する点は、非常に挑戦的である
- rmw-[implementationの名前]; 各DDS/RTPSに対するrmw側実装。github上に存在はしても、Full Supportか否かは別途確認が必要がある点に注意
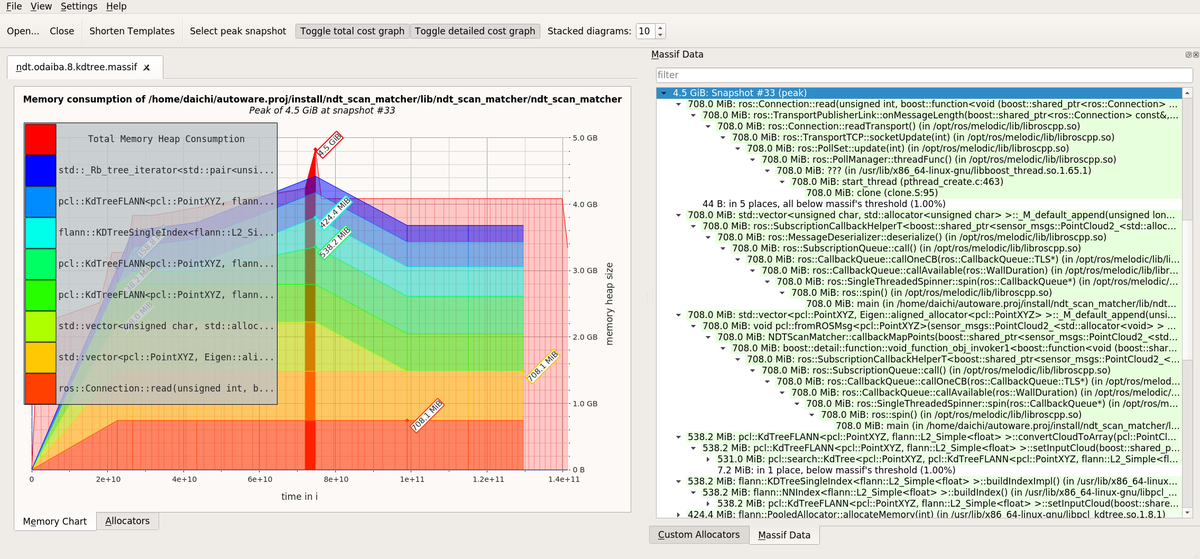
- ゼロコピー転送; 通信時にコピーが発生しない転送。process間のshared memory上を介した実装がIce-Oryx。process内のpointer passingによる転送もゼロコピー転送。転送先のみがそのデータを使用する場合に有効で、応答速度やメモリ消費量が改善する。そうでない一般の通信はコピーが必要だが、大きいデータを扱う時は注意が必要。以下の例では700MBほどの地図データが何重にもコピーされてしまっている
*1:Autoware.AIはROSで動くように設計されていたがAutoware.AutoはROS 2上で動くように設計されている





























